이번 포스팅은 "실전 시계열 분석 통계와 머신러닝을 활용한 예측 기법 책"과 "Forecasting Principles and Practice"책을 기반으로 AR, MA, ARIMA 모형을 정리하고자 합니다.,제목은 "어디까지 파봤니"로 거만하지만 사실은 많이 안 파봤고, 저도 평소에 궁금했던 증명 과정과 헷갈렸던 내용들 위주로 정리해보았습니다. 언제나 그랬듯, 파이썬 예시와 함께 합니다.
제목은 "어디까지 파봤니"로 거만하지만 사실은 많이 안 파봤고, 저도 평소에 궁금했던 증명 과정과 헷갈렸던 내용들 위주로 정리해보았습니다. 언제나 그랬듯, 파이썬 예시와 함께 합니다.
자기 회귀 모델 (AR; Autoregressive Model)
과거의 값이 현재의 값에 영향을 줄 때 사용하는 모델
자기 회귀 (AR; Autoregressive) 모델은 과거가 미래를 예측한다는 직관적인 사실에 의존합니다.
차수가 p인 AR(p) 자기 회귀 모형은 다음과 같이 쓸 수 있습니다.
yt=c+ϕ1yt−1+ϕ2yt−2+⋯+ϕpyt−p+ϵt
여기서 ϵt는 백색잡음 (white noise)자기 상관이 없는 시계열입니다.
백색 잡음은
평균이 0이고 (E(ϵt)=0)
분산은 σ2로 일정해야하고 (Var(ϵt)=σ2)
서로 다른 시점에서의 공분산도 0인 시계열 (Cov(ϵt,ϵs)=0,t=s)
을 의미합니다. 정의에서 알 수 있듯이 백색잡음은 정상성을 띱니다.
AR 식이 의미하는 바는 t시점의 값을 최대 t−p 시점 이전의 값까지 포함하여 회귀식을 완성해야 잔차 ϵt의 값이 과거의 잔차들의 값에 의존하지 않음을 의미합니다.
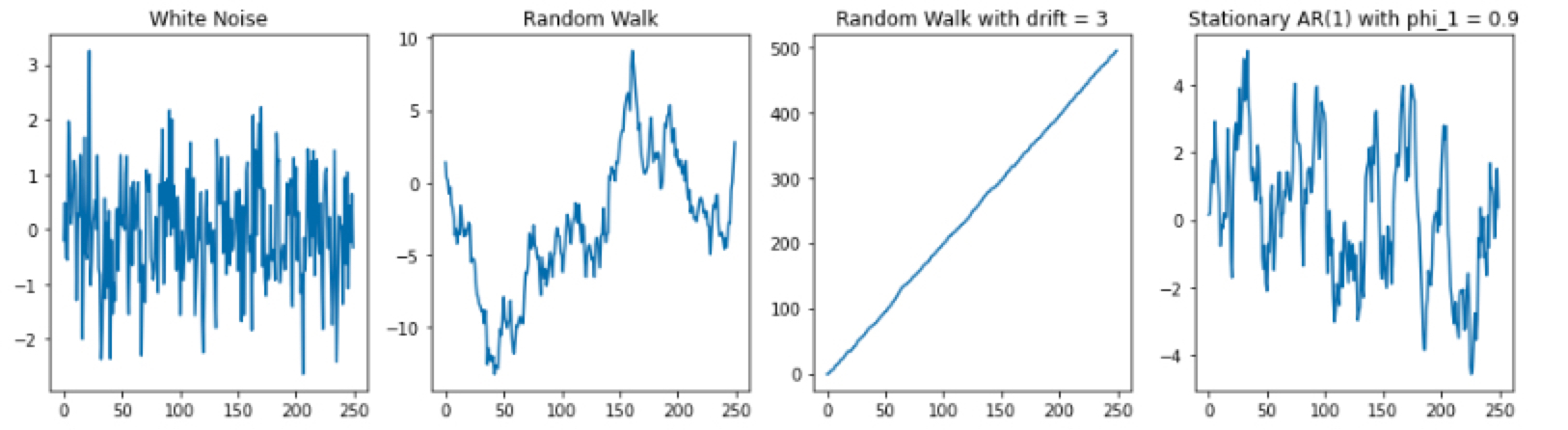
AR(1) 모형의 다양한 형태
백색 잡음 / 확률 보행 / 표류가 있는 확률 보행 / 정상성을 만족하는 모형
이를 단순화해서 yt가 그 직전 시점인 yt−1에만 의존하는 즉, 차수가 1인 AR(1) 모형을 살펴봅시다.
yt=c+ϕ1yt−1+ϵt
여기서 ϕ1과 c의 값에 따라서 AR(1)모형은 다양한 이름으로 불립니다.
백색 잡음 (White noise model)
yt=ϵt 과거의 값과 현재의 값의 상관관계가 없는, 단순한 Shock 형태
c=ϕ1=0일 때 yt는 백색잡음입니다. 백색잡음 모형은 위에서 설명했듯이, 과거의 값으로 현재의 값을 예측할 수 없는 랜덤한 상태를 의미합니다
확률 보행 (Random walk model)
yt=yt−1+ϵt, 현재의 값을 예측할 수 있는 가장 좋은 값은 어제의 값
ϕ1=1, c=0이면 yt=yt−1+ϵt로, 이 모형은 확률보행 (Random walk) 모형입니다. 이 모형은 정상성을 띠지 않습니다.
이 모형의 의미는 오늘 시계열 값 (yt)은 어제의 시계열 값 (yt−1)+ 예측할 수 없는 변화량 (ϵt)으로 설명된다는 것을 의미합니다.
결과적으로, 현재의 값을 예측할 때 가장 좋은 값은 어제의 값이다라는 뜻이죠.
이 모형은 **확률론적 추세 (Stochastic trend)**가 존재하는 가장 단순한 모형입니다.
표류가 있는 확률 보행 (Random walk model with a drift)
yt=c+yt−1+ϵt, 시간이 지남에 따라 평균적으로 값이 증가하거나 감소하는 형태
ϕ1=1, c=0이면 yt=c+yt−1+ϵt로, 여기서 상수 c를 표류 (drift)라 합니다.
그래서 이 모형은 표류가 있는 확률 보행 (Random walk with a drift) 모형입니다.
이렇게 전개가 됩니다. 이 모형은 **확정적인 추세 (Deterministic trend)**를 가지고 있고, c>0이라면 시간에 따라 평균적으로 증가하는 모습을 보입니다.
−1<ϕ1<1인 정상성을 만족하는 모형
−1<ϕ1<1인 yt=c+ϕ1yt−1+ϵt, 정상성 (Stationarity)을 띠는 AR(1) 모형
−1<ϕ1<1이면 정상성 (Stationarity)을 띠는 AR (1)모형입니다.
확률 보행 모델이 정상성을 띠지 않는 이유
확률 보행 모델은 시간이 지남에 따라 분산이 커지기 때문에 정상성을 만족하지 않습니다.
자, 그럼 눈치 상 AR(1) 모형에서 네 가지 경우를 말씀드렸는데,
여기서 정상성을 띠는 모형은 첫 번째 소개드린 백색 잡음 모형 (White noise model)과 계수가 −1<ϕ1<1 인 모형뿐이고 확률 보행 모델은 정상성을 띠지 않습니다.
AR(1)의 모형에서 정상성을 띨 조건은 −1<ϕ1<1이고, 확률 보행 모형의 ϕ1값은 1이기 때문에 그렇습니다.
그런데 왜 정상성을 띠지 않을까요?
이 확률보행 모형은 시간이 지남에 따라 분산이 증가하여 yt의 분포가 시간에 따라 변하기 때문입니다.
이를 수식을 통해 증명하고자 합니다.
다음과 같은 확률보행 모형을 가정합니다.
yt=yt−1+ϵt,ϵt∼N(0,σ2)
초기값 y0=0이라 했을 때 다음과 같이 시계열을 풀어쓸 수 있습니다.
y1y2yt=ϵ1=y1+ϵ2=ϵ1+ϵ2⋮=ϵ1+ϵ2+⋯+ϵt
이 때 yt의 분산을 구하면 잔차들의 분산의 합으로 계산되고 잔차의 분산은 σ2으로 가정했으므로 tσ2이 됩니다. 아래와 같이 말이죠!
Var(yt)=Var(ϵ1+⋯+ϵt)=Var(ϵ1)+⋯+Var(ϵt)=tσ2
참고로, ϵt는 백색잡음으로, i.i.d한 성질을 가지기 때문에 Var(∑t=1Tϵt)=∑t=1TVar(ϵt)로 쓸 수 있습니다.
그리하여 yt의 분산은 t에 의존하게 되어 t가 증가함에 따라 (시간이 지남에 따라) 분산이 커지게 됩니다. 따라서 정상성의 정의에 따라서 분산이 유한하지 않아 정상성을 띠지 않게 됩니다.
AR (1) 정상성을 만족할 조건 증명하기
이렇게 정상성이 없는 시계열에 그대로 AR 모형을 적용하게 되면 터무니없는 예측치를 내기 때문에 시계열 모형이 정상성을 띠도록 차분 / 로그 변환을 하여 모형을 적용해야 합니다.
정상성을 띠어야 하는 이유는 정상성을 띠어야 시계열의 과거, 현재, 미래의 분포가 같기 때문에 미래의 값을 예측할 수 있기 때문이죠.
통계학 수업 때 저는 AR 모형은 많이 들어봤지만 MA 모형은 얼렁뚱땅 넘어가고 ARIMA로 바로 퀀텀 점프했던 경우가 많았는데요. "도대체 어떤 데이터를 MA로 설명할 수 있을까?"에 대해 약간의 리서치를 해본 결과, 이런 좋은 예를 찾았습니다.
일별 수영장에 입장하는 사람수에 대한 모델링을 한다 가정해봅시다. 사람들은 보통 수영장을 갈 때 어떤 것을 많이 신경쓸까요? 수영장 가는 날 “비가 내리는지” 신경을 많이 쓸 것입니다. 강수 여부를 예측하기 어렵고 i.i.d를 따른다 가정했을 때, 비가 많이 오면 “weather shock”굳이 한국말로 번역하면 날씨 충격! 은 오늘 뿐 아니라 내일, 모레의 수영장에 입장하는 사람 수에 영향을 줄 것입니다. 사람들은 보통 오늘 비가 오면 기상 예보를 보면서 내일과 모레의 날씨를 가늠하곤 하죠. 또한, 비가 온다고 예상이 되면 굳이 그 날에 수영장을 가지 않을 것입니다. 엄청난 놀이기구 마니아면 몰라도 말이죠!
결과적으로, MA 모형은 “과거의 충격이 현재의 결과에 영향을 주는 경우” 사용할 수 있고, 이런 식으로 모델링이 될 것입니다:
수영장입장사람수=μ+θ1Weathert+θ2Weathert−1
여기서 날씨는 오차 (ϵt) 내지는 충격 (Shock)에 해당하며, 예측하기 어려운 변수로 가정됩니다.
MA 모형이 항상 정상성을 만족하는 이유
MA 정의 상 평균과 분산이 일정하므로 정상성을 만족합니다.
신기하지 않나요? AR(1) 모형에선 정상성을 띠기 위해 −1<ϕ1<1 조건이 필요했는데, 정의상 MA 모델은 어떠한 모수에 제약이 없어도 약한 정상성을 띱니다.
자, 그럼 또 모형을 단순화하여 MA(1) 과정에서 왜 정상성을 띠는지 알아봅시다.
yt=c+ϵt+θ1ϵt−1
약한 정상성을 띨 조건은 평균과 분산이 유한하고, 둘 다 시간에 따라서 바뀌지 않아야 합니다. MA 모델은 정의상 오차 ϵt가 평균을 0으로 하는 독립 항등 분포 (ϵt∼N(0,σ2))이기 때문에 다음과 같이 평균과 분산을 구할 수 있습니다.
여기서 y′는 차분을 구한 시계열입니다. (한 번 이상 차분을 구한 것일 수 있습니다) 또한 식을 자세히 보면 p차까지 AR처럼 과거의 y′값들이 들어가있고, q차까지 MA처럼 ϵt가 전개되어있습니다. 따라서, 모수 p,d,q는 다음과 같은 의미를 같습니다.
p: AR 부분의 차수
d: 차분의 정도
q: MA 부분의 차수
즉 ARIMA (1,0,0)이면 AR(1)모형과 같고, ARIMA(0,0,1)이면 MA(1) 모형이 됩니다.
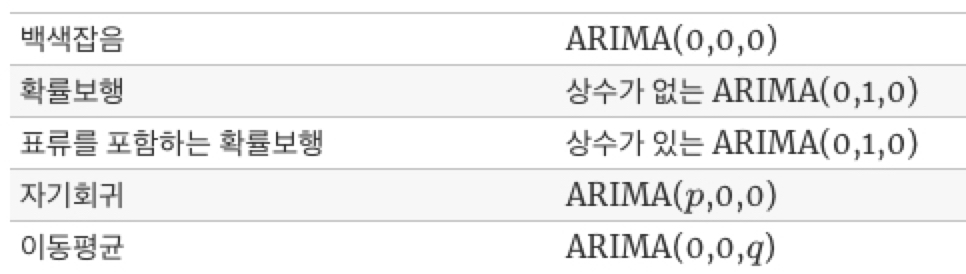
이를 일반화하여 ARIMA에 특별한 경우를 정리하면 다음과 같습니다.
참고로 ARIMA에서 "I"가 빠지면 ARMA(p,q)과정인데 이는 차분만 안했을 뿐 AR 과 MA 과정이 합쳐진 모형입니다.
실전! 시계열 자료 생성하기
이전 포스팅에서는 실제 주식 자료로 정상성을 파악했다면, 이번에는 AR, MA, ARIMA 모형을 따르는 자료를 생성해서 어떻게 생겼는지 확인하고자 합니다.
파이썬에서 시계열 분석과 관련한 패키지는 statsmodels 의 tsatime series analysis의 약자입니다. ([link])
그리고 이 패키지에서 쓸 메서드는 ArmaProcess (ar, ma)입니다. 이름에서 알 수 있듯이, AR 모형, MA 모형, ARIMA 모형 모두 한 번에 ARMA꼴로 만들어서 한 함수로 처리할 수 있도록 한 것이 특징입니다.
아래와 같이 필요한 패키지를 불러옵니다.
1 2 3
from statsmodels.tsa.arima_process import ArmaProcess import numpy as np import matplotlib.pyplot as plt
ArmaProcess (ar, ma)에 쓰이는 ARMA (p,q) 과정은 아래와 같이 정의가 됩니다.
yt=ϕ1yt−1+…+ϕpyt−p+θ1ϵt−1+…+θqϵt−q+ϵt
ARIMA에서 차분만 안했지, p차까지의 AR 계수가 있고, q차까지 MA 계수가 있는 꼴입니다. ArmaProcess (ar, ma)를 사용하려면 ARMA (p,q) 모형을 시차 - 차수 표현 (lag-polynomial representation)으로 나타낸 꼴을 이해해야 하는데요.
말은 어렵지만, 후방 이동 연산자 L를 이용해서 식을 정리하는 것을 의미합니다.
L을 후방 이동 (backshift) 연산자라 할 때, 아래와 같이 정의됩니다.
LytL2yt⋮=yt−1=yt−2
즉, 후방 이동 연산자는 시차만큼 t시점의 값에 후방 이동 연산자를 곱해줘 시계열 값을 표현하는 방식입니다.
그럼 ARMA (p,q) 과정을 L을 이용해 A⋅yt=B⋅ϵt의 형태로 정리해보겠습니다.
AR 모형이여도 ma 인풋에 L0 의 계수(즉, ϵt의 계수)에 해당하는 [1]을, MA 모형이여도 ar 인풋에 L0 의 계수(즉, yt의 계수) [1]을 넣어줘야한다는 점입니다.
AR (p) 모형 생성하기
ArmaProcess(ar = [1,-phi_1, -phi_2, ..., -phi_p], ma = [1])로 생성
위에서 AR (1) 모형의 다양한 형태를 정리하였는데요. 각 모형을 따르는 데이터를 생성해보겠습니다.
이를 위해 gen_arma_samples와 gen_random_walk_w_drift 함수를 정의하였습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# ArmaProcess로 모형 생성하고 nobs 만큼 샘플 생성 defgen_arma_samples (ar,ma,nobs): arma_model = ArmaProcess(ar=ar, ma=ma) # 모형 정의 arma_samples = arma_model.generate_sample(nobs) # 샘플 생성 return arma_samples
# drift가 있는 모형은 ArmaProcess에서 처리가 안 되어서 수동으로 정의해줘야 함 defgen_random_walk_w_drift(nobs,drift): init = np.random.normal(size=1, loc = 0) e = np.random.normal(size=nobs, scale =1)
y = np.zeros(nobs) y[0] = init
for t inrange(1,nobs): y[t] = drift + 1 * y[t-1] + e[t]
return y
그리고 백색 잡음 모형 (white_noise), 임의 보행 모형 (random_walk), 표류가 있는 임의 보행 모형 (random_walk_w_drift), 정상성을 만족하는 ϕ1=0.9인 AR(1) 모형 (stationary_ar_1)을 각각 250개씩 샘플을 생성하여 그림을 그렸습니다.
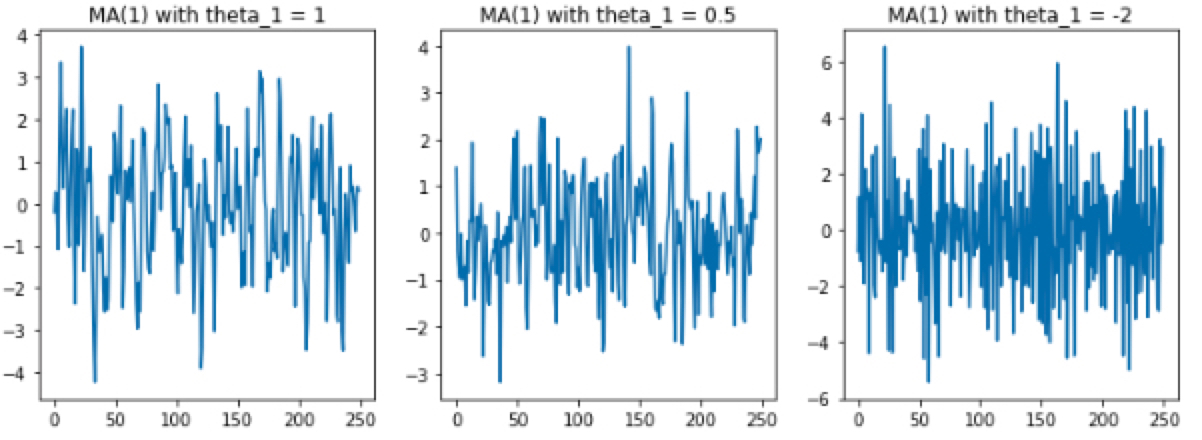
ax[0].plot(ma_1) ax[0].set_title("MA(1) with theta_1 = 1")
ax[1].plot(ma_2) ax[1].set_title("MA(1) with theta_1 = 0.5")
ax[2].plot(ma_3) ax[2].set_title("MA(1) with theta_1 = -2") plt.show()
위 그림에서 볼 수 있듯이 θ1의 값에 따라 모형 형태가 약간 다르긴 하지만 특정한 트렌드도 없고 평균과 분산이 일정하기 때문에 정상성을 만족함을 확인하실 수 있습니다.
ARIMA (p,d,q) 모형 생성하기
ArmaProcess(ar = [1,-phi_1, -phi_2, ..., -phi_p], ma = [1, theta_1,theta_2, ..., theta_q])로 생성 후 unintegrate(x, level)
ARIMA는 앞에서 봤던 AR이나 MA 생성 방법에서 한 단계 더 나아가야 합니다.
ARIMA(p,d,q) 모형은 ARMA (p,q) 모형에서 d번 차분한 값이라는 말은 즉, ARIMA (p,d,q) 모형은 원 시계열에서 d 번 차분해야 ARMA (p,q) 모형을 따름을 의미합니다.
따라서, ARIMA (p,d,q)를 따르는 데이터를 생성하기 위해선
ARMA (p,q) 과정을 따르는 데이터를 생성하고
이 데이터가 d 번 차분한 값이기 때문에 원상복귀해주는 unintegrate 함수를 사용해야 합니다. unintegrate (x, level) 에서 만약 1차 차분이라면 level = [1], 2차 차분이라면 level = [1,2]과 같이 정의해주어야 합니다. ([link])
R의 arima.sim() 함수 그립습니다… ㅎㅎ…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
np.random.seed(12345) from statsmodels.tsa.arima_model import unintegrate, unintegrate_levels
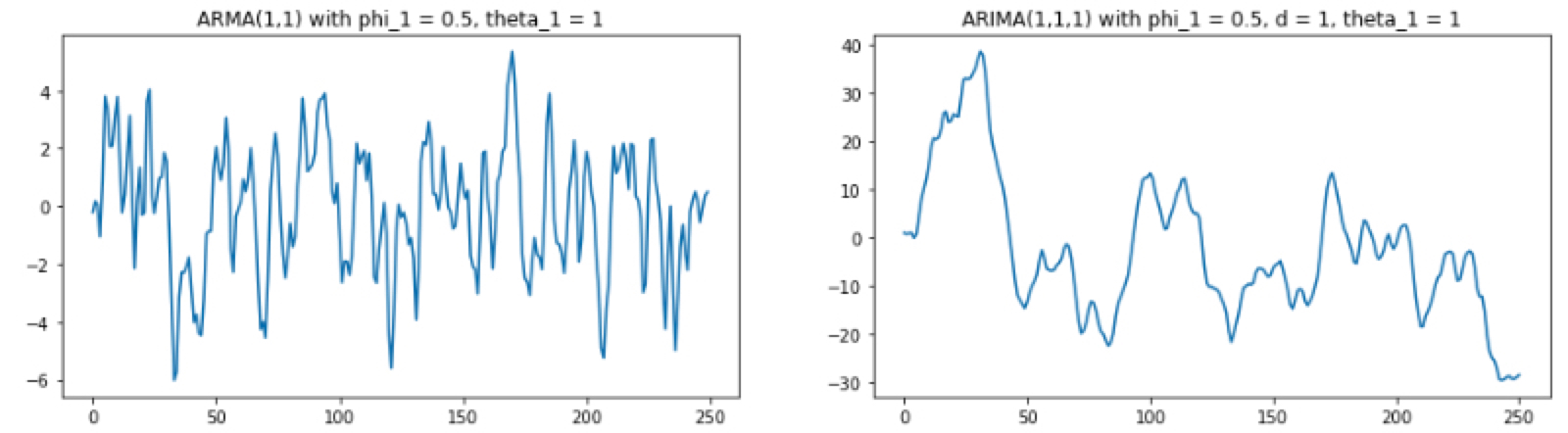
arma_1 = gen_arma_samples (ar = [1,-.5], ma = [1,1], nobs = 250) # 차분한 값이 ARMA (1,1)을 따름 arima_1 = unintegrate(arma_1, [1]) # unintegrate: 차분한 값을 다시 원상 복귀
fig,ax = plt.subplots(1,2, figsize = (16,4))
ax[0].plot(arma_1) ax[0].set_title("ARMA(1,1) with phi_1 = 0.5, theta_1 = 1")
ax[1].plot(arima_1) ax[1].set_title("ARIMA(1,1,1) with phi_1 = 0.5, d = 1, theta_1 = 1") plt.show()
위와 같이 ARMA(1,1)과 ARIMA (1,1,1)을 따르는 모형을 생성하면 다음과 같은 그림을 얻을 수 있습니다.
마치며
이렇게 AR, MA, ARIMA 모형에 대해 정리하고, 시뮬레이션을 통해서 데이터 생성까지 해보았습니다.
“파이썬으로 데이터 생성은 해봐야지” 하고 정리했는데 생각보다 tsa 패키지가 유저 친화적이지가 않네요. R 유저로써 이번엔 파이썬으로 글을 쓴 것에 대해 후회하고 있습니다.
특히 drift 가 있는 모형이나, ARIMA 모형에 대한 시뮬레이션이 아주 불편하네요! 더 좋은 방법이 있겠거니 하고 열심히 구글링을 했지만 제가 알아낸 것으로는 저 방법이 최선인 것 같습니다.
다음 글에서는 AR, MA, ARIMA 모형 및 차수 선택과 관련한 내용을 적고자 합니다.
차수 결정하는 게 사람 손을 타서 생각보다 직접 데이터에서 파악하는게 어렵더라고요.