Implicit Feedback 추천 시스템에 대한 친절한 설명
- 이 글은 Jesse님의 허락을 받고 A Gentle Introduction to Recommender Systems with Implicit Feedback
[link]을 번역한 글입니다.
추천 시스템 소개
추천 시스템은 소셜 네트워크, 엔터테인먼트 산업 등 다양한 산업에서 매우 중요합니다. 당신이 선호할만한 곡을 추천하는 것부터, 읽을만한 책을 추천하고, 입을만한 옷을 추천하는 것까지 추천 시스템은 고객들에게 제품을 더 쉽게 선택할 수 있도록 도와주고 있습니다.
의사결정에 도움을 주는 추천 시스템은 왜 그리 중요할까요? 한 논문은 이틀간 잼 가판대에 관한 실험을 진행했습니다. 한 가판대는 24개의 잼 종류가 있는 반면 두 번째 가판대는 6개만 잼이 놓여져 있었습니다. 24개의 종류를 가진 가판대에서는 3%의 고객들만이 구매한 반면, 6개의 종류를 가진 가판대는 30%의 고객들이 구매를 결정했다 합니다. 거의 10배에 가깝게 구매가 증가한 것이죠!
특히 온라인 쇼핑몰에서 추천 시스템은 선택 범위를 좁혀주기 때문에 매우 큰 효과를 가집니다. 과거 Netflix에 종사하다 Quora에 재직 중인 Xavier Amatriain는 2014년에 카네기 멜론 대학에서 추천 시스템에 대한 강연을 했는데요. 그가 소개한 추천 시스템에 대한 주요 통계 자료는 다음과 같습니다.
- 넷플릭스에서는 고객들이 본 영화 중 2/3는 추천된 영화입니다.
- 구글에서는 뉴스 추천으로 CTR을 38%나 향상시켰습니다.
- 아마존에서는 구매의 35%가 추천으로부터 나옵니다.
이와 더불어 Hulu에서는 단순하게 가장 인기있는 상품을 추천했던 것보다 추천 시스템을 이용한 결과, CTR이 3배 이상 증가했다 보고했습니다. 잘만 활용한다면 추천 시스템은 기업에게 큰 도움을 줄 수 있습니다.
자, 그럼 고객 정보와 아이템에 대해 충분한 정보가 있다 가정하고 추천 시스템을 구축한다 해봅시다. 어떻게 구축할 수 있을까요? 구축하기 위해서는 다음과 같은 요인들을 고려해야 합니다.
- 유저와 아이템에 대한 데이터의 종류
- scale 능력
- 추천의 투명성
이 포스트에서는 위의 세 가지 요인들에 대해 다루고, 고려할 요인에 필요한 기본적인 방법론에 대해 정리하고자 합니다.
콘텐츠 기반 추천 (Pandora)
스트리밍 뮤직 기업인 Pandora에서는 음악 게놈 프로젝트의 일환으로 자신들이 갖고 있는 음악들의 고유한 특징들을 추출하기로 결정했습니다. 대부분의 곡은 450개 남짓한 특징을 가진 특징 벡터 (feature vector)에 기반하고 있습니다. 이러한 특징들로 추천 시스템을 이진 분류 (binary classification) 문제로 치환해 모형을 구축할 수 있습니다. 즉, 특정한 유저의 플레이리스트를 바탕으로 훈련 데이터를 만들어서 그 유저가 특정한 노래를 좋아할 확률을 추정할 수 있도록 전통적인 머신러닝 방법들을 사용할 수가 있는거죠. 즉, 콘텐츠 기반 추천은 좋아할 확률이 가장 높은 곡들로 추천하게 됩니다.
그러나 대부분의 회사들은 제품의 특징에 대한 데이터를 따로 갖고 있지 않습니다. Pandora도 곡들의 특징을 추출하기까지 여러 해가 걸렸다고 합니다. 이런 한계로 인해 콘텐츠 기반 추천은 최우선 순위가 아닐 수 있습니다.
인구 통계 (Demographic) 기반 추천 (Facebook)
만약 Facebook이나 LinkedIn처럼 유저에 대한 인구 통계학 정보가 많다면, 비슷한 유저나 그들의 과거 행동에 기반해서 추천을 할 수 있습니다. 콘텐츠 기반 방법과 유사하게 유저들의 고유한 특징 벡터를 뽑아내고, 특정한 아이템을 좋아할 확률을 예측할 수 있는 모델을 만들 수 있습니다.
그러나, 이 또한 유저들에 대한 정보가 많이 필요하기 때문에 콘텐츠 기반 추천과 마찬가지로 쉽지 않은 선택입니다. 따라서, 만약에 아이템과 유저에 기반한 자세한 정보에 대해 신경쓰고 싶지 않다면, 협업 필터링이 강력하고 효율적인 방법이 될 수 있습니다.
협업 필터링 (Collaborative Filtering)
협업 필터링은 유저와 아이템간의 관계만 사용하고, 그 자체의 정보에 대해서는 사용하지 않습니다. 필요한 정보는 각 유저와 아이템 간 상호작용 (interaction)으로 인해 나온 평점입니다. 참고로 추천 시스템에서 상호작용은 유저가 특정한 아이템에 평점을 남기거나 구매하는 행위를 의미하고 피드백 (feedback)이라고도 불립니다. 이러한 상호작용은 명시적(explicit), 암시적(implicit) 상호작용으로 나눌 수 있습니다.
- 명시적 (Explicit): 점수, 평점, 좋아요와 같이 명시적으로 점수를 매긴 것
- 암시적 (Implicit): 클릭, 노출, 구매로 추정할 수 있는 선호도로, 명시적 상호작용만큼 명확하지 않음
가장 쉬운 예시는 숫자로 매길 수 있는 영화 평점입니다. 우리는 평점을 통해 유저가 영화를 즐겼는지를 알 수 있습니다. 이런 평점 데이터는 명시적 상호작용이라 할 수 있습니다.
그러나, 대부분 사람들은 평점을 전혀 남기지 않는다는 문제가 있습니다! 따라서, 사용가능한 데이터가 매우 희귀합니다. 그 대신 Netflix는 최소한 유저가 어떤 콘텐츠를 시청했는지의 정보를 얻을 수 있습니다. 이런 시청 정보에 대한 데이터는 암시적 상호작용입니다. 그러나, 이 유저가 특정 프로그램을 시청했다고 해서 그 프로그램을 좋아한다고 말하기 어렵습니다. 따라서, 명시적 상호작용에 비해 암시적 상호작용은 어떤 콘텐츠를 선호하는지 추천하는 일이 더 어려운 일입니다.
이런 단점에도 불구하고, 암시적 피드백은 중요합니다. Hulu라는 회사에서는 추천 시스템에 대한 기사에서 다음과 같이 언급합니다.
Hulu에서의 암시적 데이터의 양은 명시적 피드백의 양을 압도하기 때문에, 우리의 추천 시스템은 암시적 피드백 데이터를 갖고 우선적으로 설계되어야 한다.
더 많은 데이터가 더 좋은 모형을 의미하기 때문에, 암시적 피드백 데이터를 구축하는데 힘써야한다는 것입니다. 암시적 피드백 데이터를 이용한 협업 필터링에는 많은 방법들이 있지만, 이 글에서는 Spark의 implicit 라이브러리에서 쓰는 방법인 ALS (Alternative Least Squares)에 대해 서술하겠습니다.
ALS (Alternative Least Squares)
ALS은 암시적 피드백 데이터를 협업 필터링을 통해 추천 시스템을 구현하기 위한 알고리즘입니다.
본격적으로 예시에 들어가기 전에, 이 방법이 어떻게 작동하는지 직관적으로 설명하고 왜 스파크에서 유일하게 선택되었는지 설명하고자 합니다. 앞에서 협업 필터링은 유저나 아이템에 대한 정보를 전혀 이용하지 않는다고 말했습니다. 그러면 어떻게 유저와 아이템이 서로 연관있다고 정의할 수 있을까요?
정답은 **행렬 분해 (Matrix Factorization)**입니다. 행렬 분해는 차원 축소 (관련한 정보는 남기되 피처의 개수를 줄이고 싶을 때)에서 자주 사용되는 방법입니다. 이는 주성분 분석PCA; Principal Component Analysis과 고유값 분해 SVD; Singular Value Decomposition과 일맥상통하죠.
ALS의 행렬 분해의 핵심은
- 매우 큰 유저-아이템 행렬로부터
- 숨겨진 피처들을 뽑아내서
- 이들을 훨씬 작은 유저들의 특징을 담은 행렬과 아이템 특징을 담은 행렬로 분해하는 것입니다.
아래 사진에서 보듯이, 행렬 은 행렬입니다. 은 유저 수, 은 아이템 수를 의미합니다. 이 행렬은 매우 희소 (sparse)한데, 유저들이 몇 개들의 아이템과 상호작용했기 때문입니다. 이 행렬을 두 개의 작은 행렬로 분해할 수 있습니다: (1) 한 행렬은 차원을 가진 각 유저의 특징들을 담은 잠재 유저 행렬 이고, (2) 두 번째 행렬은 행렬을 가진 아이템들의 특징을 담은 잠재 아이템 행렬 입니다. 이 두 행렬을 곱하면 원본 행렬 과 유사한 값을 내지만, 두 행렬은 원본 행렬과 달리 아이템과 유저에 대한 개의 잠재적 특징을 가진 빽빽한 (dense) 행렬입니다.
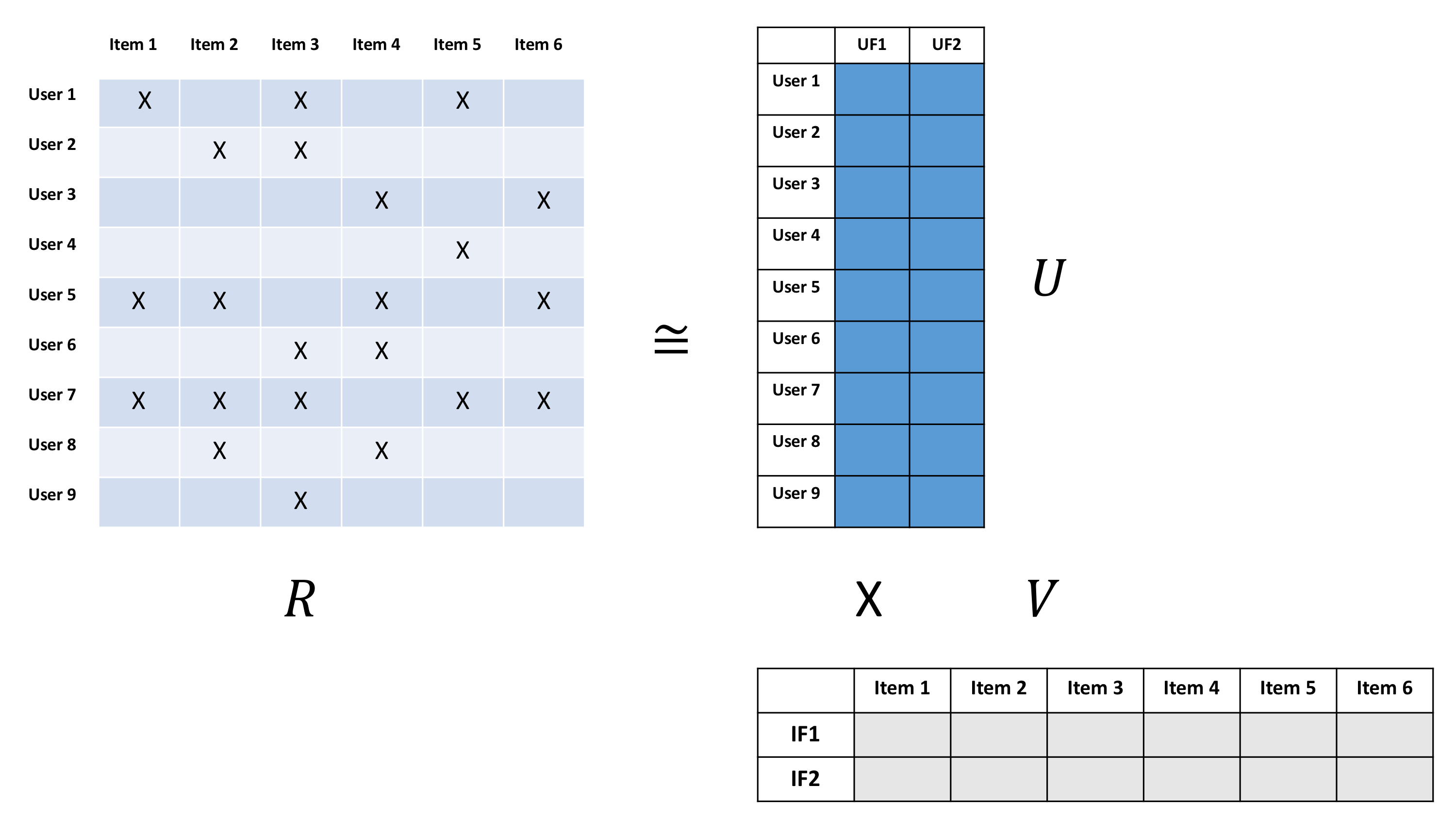
와 행렬을 풀기 위해서는 SVD를 사용하거나, 이를 근사한 ALS를 적용할 수 있습니다. SVD는 매우 큰 행렬의 역행렬을 구해야하기 때문에 컴퓨터 연산이 복잡한 반면,
ALS는 한 번에 한 특징 벡터 (feature vector)만 추출하기만 하면 되기 때문에 병렬적으로 빠르게 처리할 수 있습니다. 그렇기 때문에 스파크에서 이 방법을 사용한 큰 이유라 생각합니다. ALS 방법은 다음과 같습니다.
- 먼저, 를 랜덤하게 초기화하고 의 해를 구합니다.
- 다시 돌아가 의 해를 이용해 의 해를 구합니다.
- 을 최대한 근사시키는 수렴 값을 얻을 때까지 반복합니다.
이 연산이 끝나면 와 를 곱해 특정한 유저/아이템 상호작용에 대한 평점을 예측할 수 있습니다. 이것이 Hu, Koren, and Volinsky의 Collaborative Filtering for Implicit Feedback Datasets에서 사용한 ALS 방법입니다. 이제 이 논문에서 사용된 방법을 실제 데이터에 적용해보고, 추천 시스템을 구축해보겠습니다.
데이터 설명
예시는 "Online Retail"라 불리는 데이터 셋으로, UCI Machine Learning repository에서 가져왔습니다 (여기에서 해당 데이터를 찾을 수 있습니다). 이 데이터는 영국에 있는 온라인 소매 기업의 8개월 간의 구매 기록을 담고 있습니다.
먼저 필요한 라이브러리를 불러오고 데이터를 로드하겠습니다.
1 | import pandas as pd |

해당 데이터는 구매 목록에 대한 송장 번호 (InvoiceNo), 아이템 ID (StockCode), 아이템에 대한 설명 (Description), 구매량 (Quantity), 구매 일자 (InvoiceDate), 아이템 가격 (UnitPrice), 고객 ID (CustomerID), 고객의 국적 (Country) 컬럼으로 이루어져 있습니다.
데이터 전처리
먼저, 결측치가 있는지 확인하겠습니다.
1 | retail_data.info |
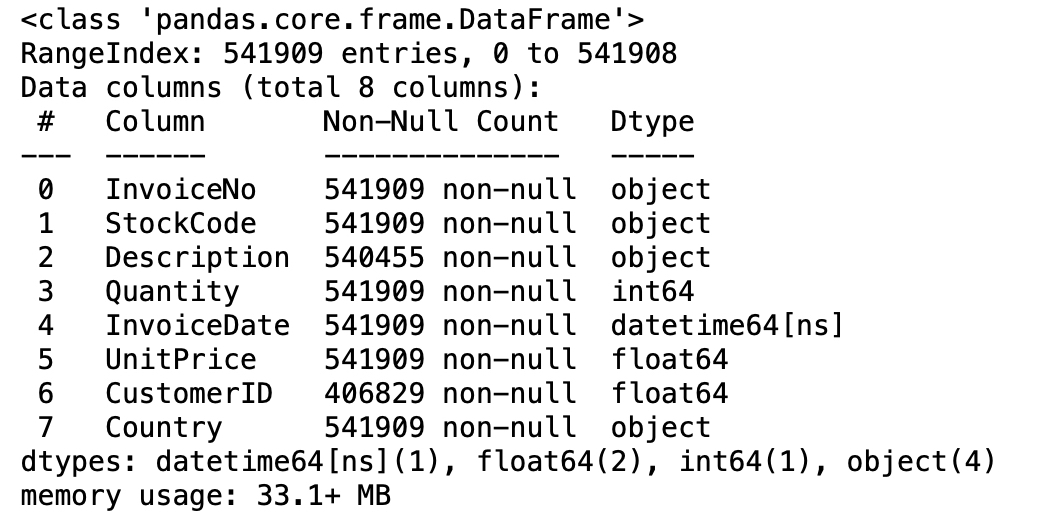
대부분의 컬럼에는 결측치가 없지만 CustomerID에 결측치가 좀 있군요. CustomerID가 결측이면 누가 어떤 항목을 샀는지 모르기 때문에 결측치를 제거해야 합니다.
1 | # 1. CustomerID가 NA인 것을 지워줌 |
결측을 제거하니 406,829행이 되었습니다.
다음은 아이템 ID에 따른 아이템 설명 테이블 item_lookup을 만듭니다. 이 테이블은 이후에 추천한 아이템이 어떤 아이템이고, 고객이 어떤 아이템을 구매한 건지 파악하기 위해 필요합니다.
1 | item_lookup = cleaned_retail[['StockCode','Description']].drop_duplicates() |
ALS 알고리즘의 입력값 형태를 만드려면 데이터를 변형해야 합니다. 유니크한 고객 ID를 행렬의 행으로, 유니크한 아이템 ID를 행렬의 열로 만듭니다. 행렬의 값은 각 유저가 각 아이템을 구매한 총 횟수입니다. 이런 행렬을 **희소 행렬 (Sparse Matrix)**라 합니다.
1 | # matrix가 매우 크기 때문에 Sparse matrix로 바꾸어주어서 |
grouped_purchased 테이블을 보면 고객 별로 특정 StockCode를 가진 항목들을 8개월 동안 얼마나 구매했는지를 Long Table 형태로 보여줍니다.
이제 이를 행은 고객 ID, 열은 아이템 ID (StockCode)로 두고 구매 수량 (Quantity)을 행렬 값으로 두는 희소 행렬을 만듭니다.
1 | customers = list(np.sort(grouped_purchased['CustomerID'].unique())) |
purchase_sparse 행렬은 4,327명의 고객과 3,650개의 아이템으로 이루어져 있습니다. 이런 유저/ 아이템 간 상호작용은 265,221개에 달합니다. 이렇게 만든 희소 행렬이 얼마나 비었는지 보기 위해 희소성 (Sparsity)를 계산할 수 있습니다. 희소성은 행렬에 얼마나 0 값이 많은지를 보여줍니다.
1 | # Sparsity: 얼마나 비어있나? |
상호작용 행렬의 98.3%이 비어있습니다. 협업 필터링을 구축하기 위해서 필요한 희소성은 약 99.5%까지 가능합니다. 저희가 구한 희소행렬은 98.3%이니까 협업 필터링을 무난하게 구축할 수 있습니다.
Train, Validation 세트 만들기
일반적인 머신러닝에서는 훈련 데이터로 만든 모형이 얼마나 새로운 데이터에 잘 작동하는지 테스트해야 합니다. 훈련 데이터로부터 테스트 데이터를 따로 만들어서 할 수 있죠.
그러나 협업 필터링에서는 적절한 행렬 분해 (matrix factorization)을 하기 위해서 모든 유저/아이템 상호작용 데이터를 사용해야 합니다. 결과적으로 모형을 훈련시킬 때 일정한 확률로 랜덤하게 뽑힌 유저/아이템 상호작용을 숨겨야 합니다. 이후, 테스트 단계에서는 얼마나 유저가 실제로 추천된 아이템을 구매했는지 파악할 수 있습니다. 이상적으로는 A/B 테스트를 통해 추천 효과를 검증할 수 있습니다.
그럼 어떻게 일정한 확률로 데이터를 숨길 수 있을까요?
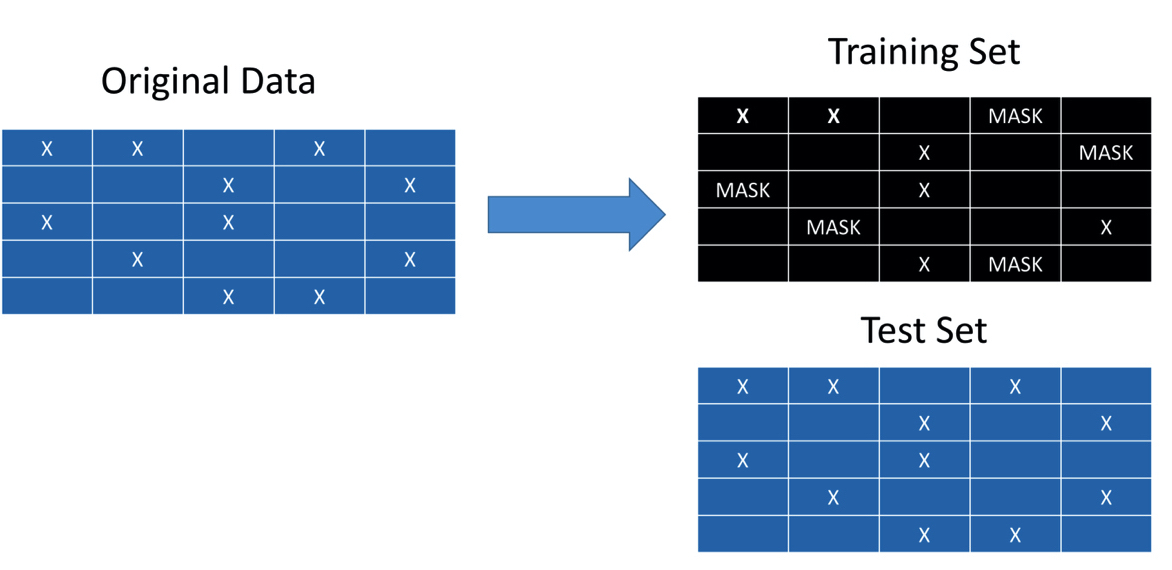
훈련 데이터는 랜덤하게 일정한 확률로유저/아이템 상호작용 몇 개를 가려 고객이 그 아이템을 구매한 적이 없는 것처럼 만듭니다 (= 몇 개의 구매 수량을 0으로 채워넣습니다). 그리고 테스트 데이터는 원본 데이터에서 구매한 이력이 있으면 1, 없으면 0으로 채운 행렬입니다. 이런 방식으로 데이터를 세팅하면, 테스트 데이터에서 얼마나 유저가 실제 구매한 아이템이 추천됐는지 파악할 수 있습니다. 만약 유저가 추천된 아이템을 실제 구매한 경우가 많을 경우 추천 시스템이 제대로 작동한다 말할 수 있겠죠.
자 이제 훈련 데이터를 만들어 봅시다.
1 | def make_train (matrix, percentage = .2): |
이제 Hu, Koren, Volinsky의 논문에서 쓰인 ALS (Alternating Least Squares)를 구현해보겠습니다.
암시적 피드백을 위한 ALS 알고리즘 구현하기 (손코딩)
Collaborative Filtering for Implicit Feedback Datasets에서 ALS 관련 수식은 다음과 같습니다.
먼저, 희소 평점 행렬 (product_train)을 신뢰 행렬 (Confidence matrix)로 만듭니다.
여기서 는 번째 유저의 번째 아이템에 대한 신뢰 행렬입니다. 는 선호도 (저희 예시에서는 구매량)에 대한 스케일링 term이고 는 저희의 구매량에 대한 원본 행렬에 해당합니다. 논문에서는 에 대한 초기값으로 40을 제안합니다.
ALS의 목적은 번째 유저의 벡터와 번째 아이템에 대한 벡터를 찾아서 유저 선호도 를 구성하는 것입니다. 유저 선호도 는 유저 벡터 와 아이템 벡터 의 내적 (inner product)으로 표현됩니다.
결국 선호도 행렬 를 만드는데 이를 유저 행렬 과 아이템 행렬 로 분해하는 것이죠 (). 이는 명시적 피드백 데이터에서 하는 행렬 분해 방법과 비슷하지만 두 가지 차이점이 있습니다.
- 유저마다 달라지는 신뢰도 (confidence level)에 대해 설명해야 하고
- 최적화가 모든 , 쌍에 대해 이루어져야한다는 것입니다.
결과적으로 다음과 같은 비용 함수를 최소화하여 , 벡터들을 구할 수 있습니다.
위의 식을 에 대해 편미분하면 비용 함수를 최소화하는 를 analytic하게 구할 수 있습니다:
저자들은 위의 식에서 컴퓨터 계산량을 줄일 수 있도록 선형대수를 이용해 다음과 같이 식을 바꾸어 계산하였습니다:
마찬가지로 아이템 벡터 를 계산하기 위한 식은 다음과 같습니다:
위의 두 식은 수렴할 때까지 앞 뒤로 반복하게 됩니다. 또한 정규화 term인 과 선호 여부를 보여주는 선호 행렬 (구매가 있으면 1, 없으면 0의 값을 갖는 이진화된 행렬)는 훈련 단계에서 과적합되지 않도록 막아줍니다.
1 | def implicit_weighted_ALS(training_set, lambda_val =.1, alpha = 40, n_iter = 10, rank_size = 20, seed = 0): |
자 이제, 한 번의 반복으로 얼마나 걸리는지 봅시다. 20개의 잠재 특성, , 로 했을 때 90초 정도 걸리네요.
1 | user_vecs, item_vecs = implicit_weighted_ALS(product_train, lambda_val = 0.1, alpha = 15, iterations = 1,rank_size = 20) |
이제 특정한 유저의 예측된 평점을 구하려면 유저 벡터와 아이템 벡터의 내적곱을 하면 됩니다. 첫 번째 유저를 살펴봅시다.
1 | first = user_vecs[0].dot(item_vecs).toarray() # 1x3650 |
1 | array([0.19375569, 0.05482773, 0.00230204, 0.01303025, 0.04740501]) |
이 값은 첫 번째 유저의 3,664개 중 첫 5개 아이템에 대한 평점입니다. 첫 번째 유저는 이 다섯 개중에 첫번째 상품을 가장 높게 평가했네요. 그러나, 한 번만 반복한 결과이기 때문에 여러 번 반복하려면 더 성능이 좋은 코드가 필요할 것 같군요.
빠르게 ALS 구현하기
위의 코드는 반복문이 있어서 병렬적으로 유저와 아이템 벡터를 각각 처리하기 어렵습니다. 대신 implicit라이브러리를 이용하면 Cython과 OpenMP를 이용해 병렬적으로 모형을 처리할 수 있기 때문에 훨씬 빠르게 ALS를 구현할 수 있습니다.
1 | import implicit |
이 라이브러리에서는 에 대한 input이 지정되어 있지 않기 때문에, 훈련 데이터에 를 곱한 신뢰 행렬 자체를 input으로 지정합니다. 또한 행렬의 형태를 double로 지정해야 합니다.
1 | alpha = 15 |
훨씬 빠르게 모형이 적합됨을 확인할 수 있었습니다. 이제 모든 유저와 아이템에 대한 평점이 계산됐습니다. 그러면 어떻게 이 모형이 잘 적합됐는지 알까요?
추천 시스템 평가하기
훈련 데이터 중 20%는 가려졌다는 사실을 기억하시나요? 이를 이용해서 추천 시스템의 성능을 평가할 것입니다. 결과적으로 유저마다 예측 평점이 높은 아이템 (추천할 아이템)이 실제로 구매한 아이템인지를 보아야 합니다. 흔히 쓰이는 지표는 ROC 커브입니다. ROC 커브 밑에 차지하는 면적이 넓을수록 추천할 아이템과 실제 구매한 아이템이 비슷함을 의미합니다. 이 면적을 AUC (Area Under the Curve)라 부릅니다.
이를 위해서 가려진 정보가 있는 아이템을 가진 유저마다 AUC를 구하는 함수가 필요합니다. 또한 추천 시스템과 비교하기 위해서 가장 인기있는 아이템을 기반으로 추천했을 때 AUC는 어떤지도 계산할 것입니다.
1 | from sklearn import metrics |
자 이제 이 auc_score함수를 helper 함수로 써서 가려진 유저들의 AUC를 계산할 것입니다.
1 | def calc_mean_auc(training_set, altered_users, predictions, test_set): |
1 | (0.869, 0.814) |
위의 코드 결과를 통해 우리의 추천 시스템이 가장 인기있는 아이템 기반 알고리즘보다 나은 성능을 낸다는 것을 알았습니다. ALS 기반 추천 시스템은 평균 0.87의 AUC를 갖는 반면, 인기있는 아이템 기반 알고리즘은 그보다 낮은 0.814의 AUC를 갖습니다. 위에서 정한 모수들을 바꿔가면서 더 높은 AUC를 가질 수 있는지 조정할 수 있습니다. 이상적으로는 교차 검증을 통해서 어떤 모수가 가장 좋은지 파악할 수 있습니다.
추천하기
인기 기반 추천보다 ALS 기반 추천이 더 나은 성능을 낸다는 것을 알았습니다. 이제 어떻게 특정한 유저에게 추천이 되는지 확인해봅시다.
먼저, 훈련 데이터에서 유저가 이미 구매한 아이템이 무엇인지 파악해야 합니다. get_items_purchased 함수는 특정 유저가 구매한 목록을 보여줍니다.
1 | def get_items_purchased(customer_id, mf_train, customer_list, products_list, item_lookup): |
1 | get_items_purchased(12347, product_train, customers_arr, products_arr, item_lookup) |
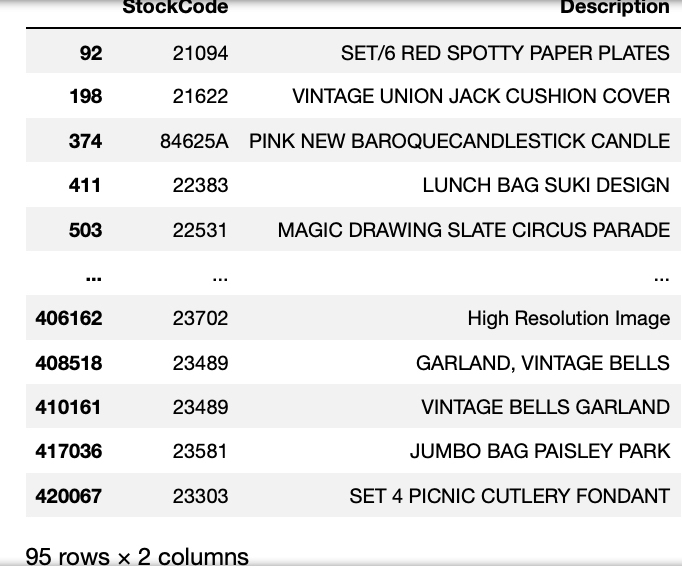
위의 결과에 따르면 12347의 고객 ID를 가진 고객은 총 98개의 아이템을 구매했습니다.
마지막으로, 구매하지 않은 아이템 중 추천할 아이템을 뽑는 함수 rec_items를 사용합니다.
1 | def rec_items(customer_id, mf_train, user_vecs, item_vecs, customer_list, item_list, item_lookup, num_items = 10): |
예를 들어 고객 ID가 12363인 유저의 실제 구매목록과 추천된 아이템을 비교하면 다음과 같습니다.
-
실제 구매 목록: 식기 세트, 종이 접시, 물병 가방, 크리스마스 관련 물품, 캔들, 열쇠고리 등
1
get_items_purchased(12361, product_train, customers_arr, products_arr, item_lookup)
-
추천 아이템: 가족 앨범 사진틀, 핑크 식기 세트, 펠트 가방 키트, 캔들, 사진틀 등
1
rec_items(12361, product_train, user_vecs, item_vecs, customers_arr, products_arr, item_lookup, num_items = 10)
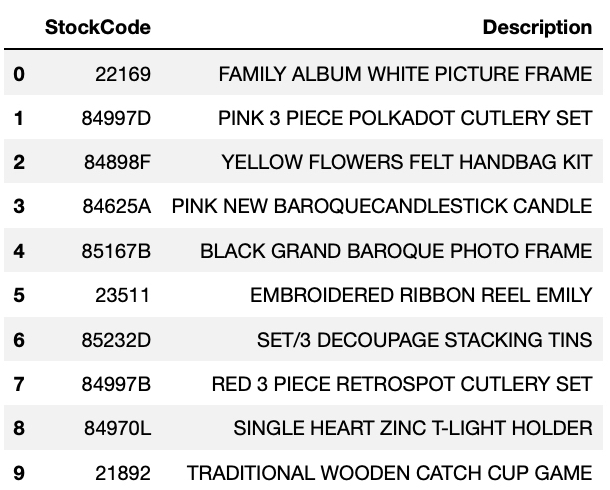
이 둘을 비교해보면 12361 id를 가진 유저는 식기 세트 (cutlery set)를 많이 구매했는데, 추천 목록에서는 아직 구매하지 않은 핑크색, 빨간색 식기 세트를 추천하고 있습니다. 또한 가족 앨범을 위한 사진틀이 1순위로 추천됐는데 아마도 해당 유저가 구매한 아이템들이 가족을 가진 아내들이 많이 사는 아이템이지 않을까 싶습니다. 이렇게 추천 시스템이 보기에도 알맞게 추천되고 있음을 확인할 수 있습니다.
이 글에서는 어떻게 암시적 피드백 데이터에서 추천 시스템이 작동하는지를 배웠습니다. 전체 코드는 여기에서 확인하실 수 있습니다.
다음 글에서는 LightFM이라 불리는 파이썬 라이브러리를 이용한 추천 시스템에 대해 파보려 합니다 :>