10분 만에 구현하는 BigQuery K-평균 클러스터링 모델
- 사진에서 볼 수 있듯이 이번 포스팅에서는 쉽게 BigQuery ML 줄여서 “BQML”를 이용해 K-평균 클러스터링을 구현하는 방법에 대해 알아보고자 합니다.
- 자세한 내용은 BigQuery ML k-평균 클러스터링 모델 만들기 페이지를 참조해주시길 바랍니다.
- 또한 성윤님의 BigQuery의 모든 것 입문편도 보시는 것을 추천합니다!
Introduction
요즘 빅쿼리를 사용할 일들이 종종 있어 "배워야지"하기만 하고 아직 실천을 하지 못했는데요. 최근에 또 구글 빅쿼리 완벽 가이드도 샀겠다, 구글 빅쿼리 강의도 흘려 들었겠다 하여 한 번 공부해볼까?하는 마음에 구글 빅쿼리 튜토리얼을 읽게 되었습니다.
그 도중 BigQuery ML k-평균 클러스터링 모델 만들기가 딱 눈에 띄여서 한번 실습해봤는데, 생각보다 쉽게 할 수 있어서 이를 공유해야겠다는 기쁜 마음에 이 글을 쓰게 되었습니다.
기존에 SQL 언어에 익숙하신 분이라면 어렵지 않게 따라할 수 있을 것으로 보입니다.
GCP 새 프로젝트 만들기
전 이미 프로젝트가 있었지만, 가이드를 위해 Google Cloud Platform GCP 콘솔 [link]에 들어가서 새 프로젝트를 생성해보았습니다.
먼저, 좌측 상단에서 프로젝트 선택을 클릭하고 새 프로젝트를 눌러 프로젝트를 생성합니다.
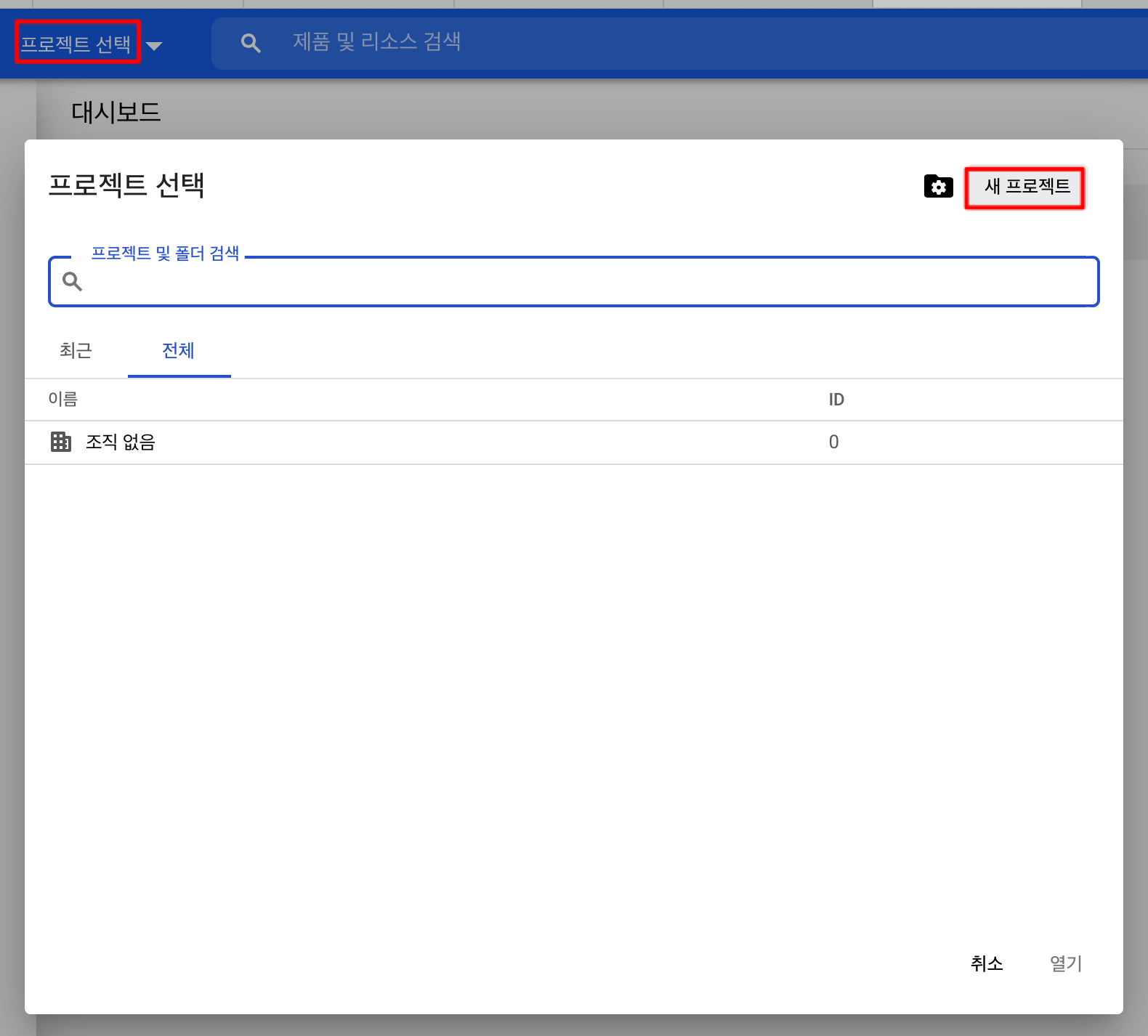
그럼 프로젝트 이름을 적당히 짓고 만들기를 클릭하면 프로젝트가 생성됩니다.
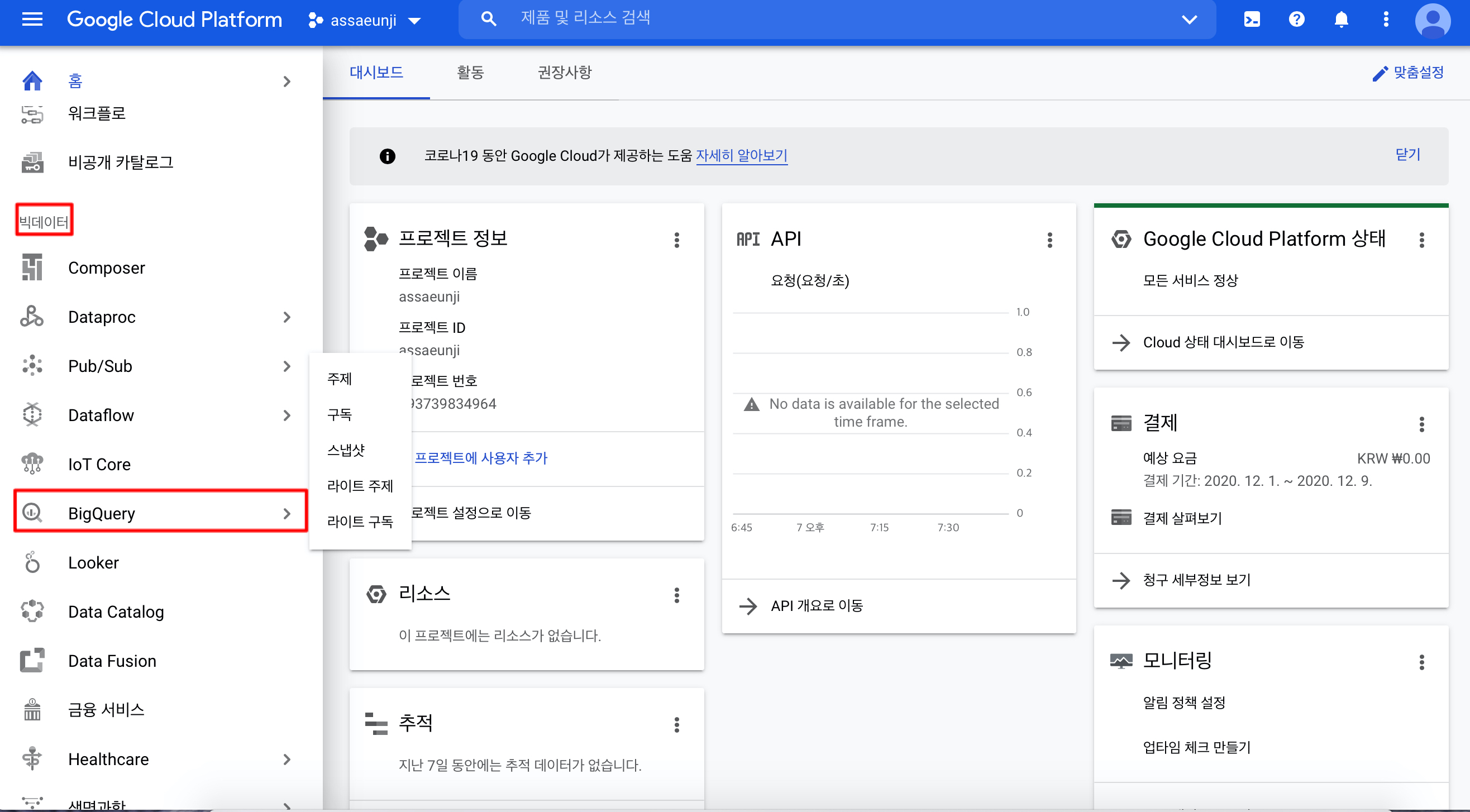
생성된 프로젝트에 가면 대시보드 형태로 내 프로젝트 정보를 볼 수 있는데요. 저희는 BigQuery를 이용하기 때문에 좌측 바에서 빅데이터 > BigQuery를 클릭해 편집기 창으로 이동합니다.
런던 자전거 공개 데이터세트 불러오기
BigQuery에서는 여러 데이터세트를 공개하고 있는데 이번 포스팅에서는 런던 자전거 데이터 세트를 이용해 K-means를 구현할 것입니다.
이를 위해서, 먼저 탐색기에서 데이터 추가를 누르고 공개 데이터세트 탐색하기를 눌러 "London Bicycle Hires"을 검색해 클릭합니다.
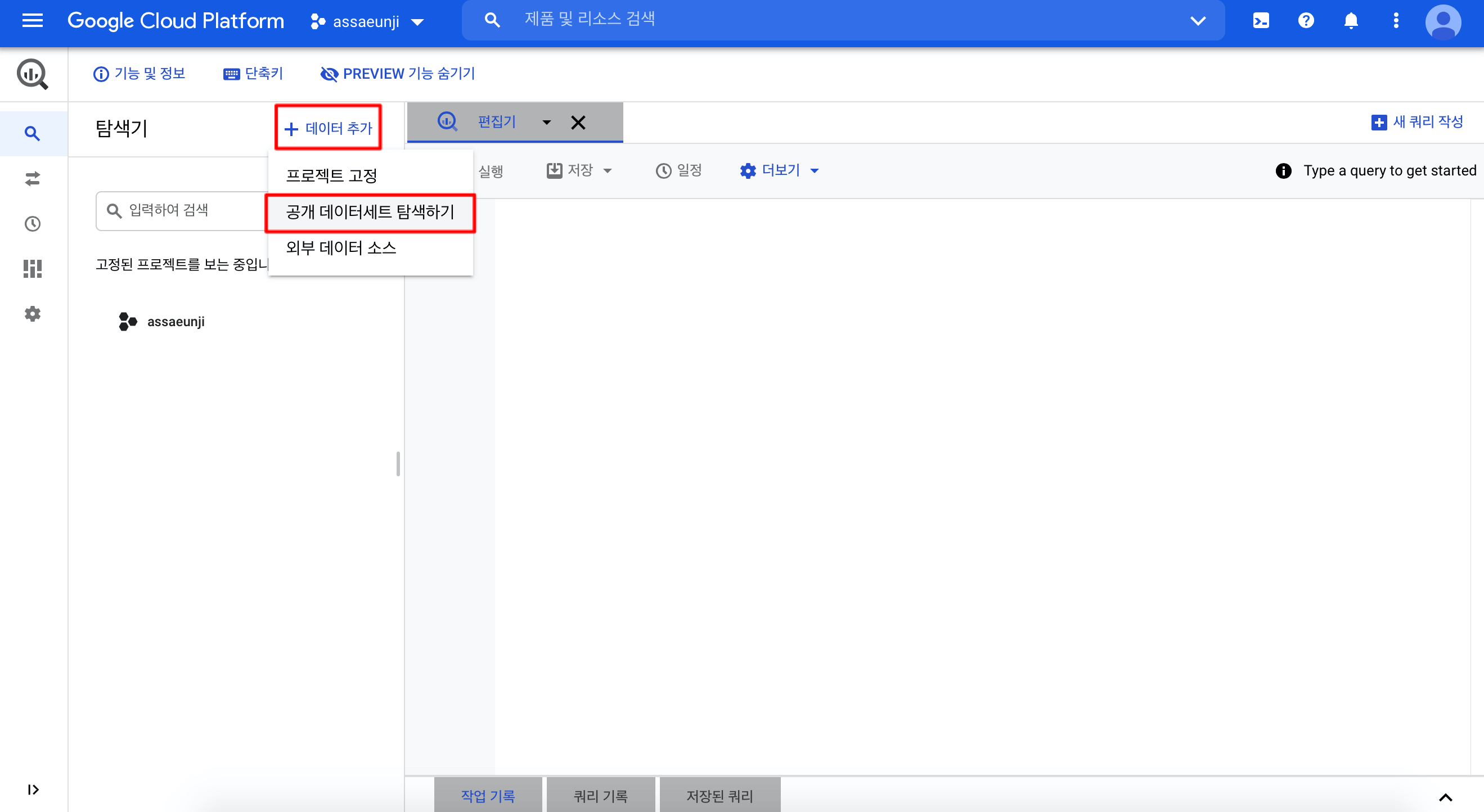
데이터세트를 불러오면 편집기의 탐색 창에서 bigquery-public-data라는 DB가 생성되었음을 볼 수 있습니다. 이 DB를 클릭해 스크롤을 내려서 london_bicycles 데이터세트가 있다면 잘 불러온 것입니다!
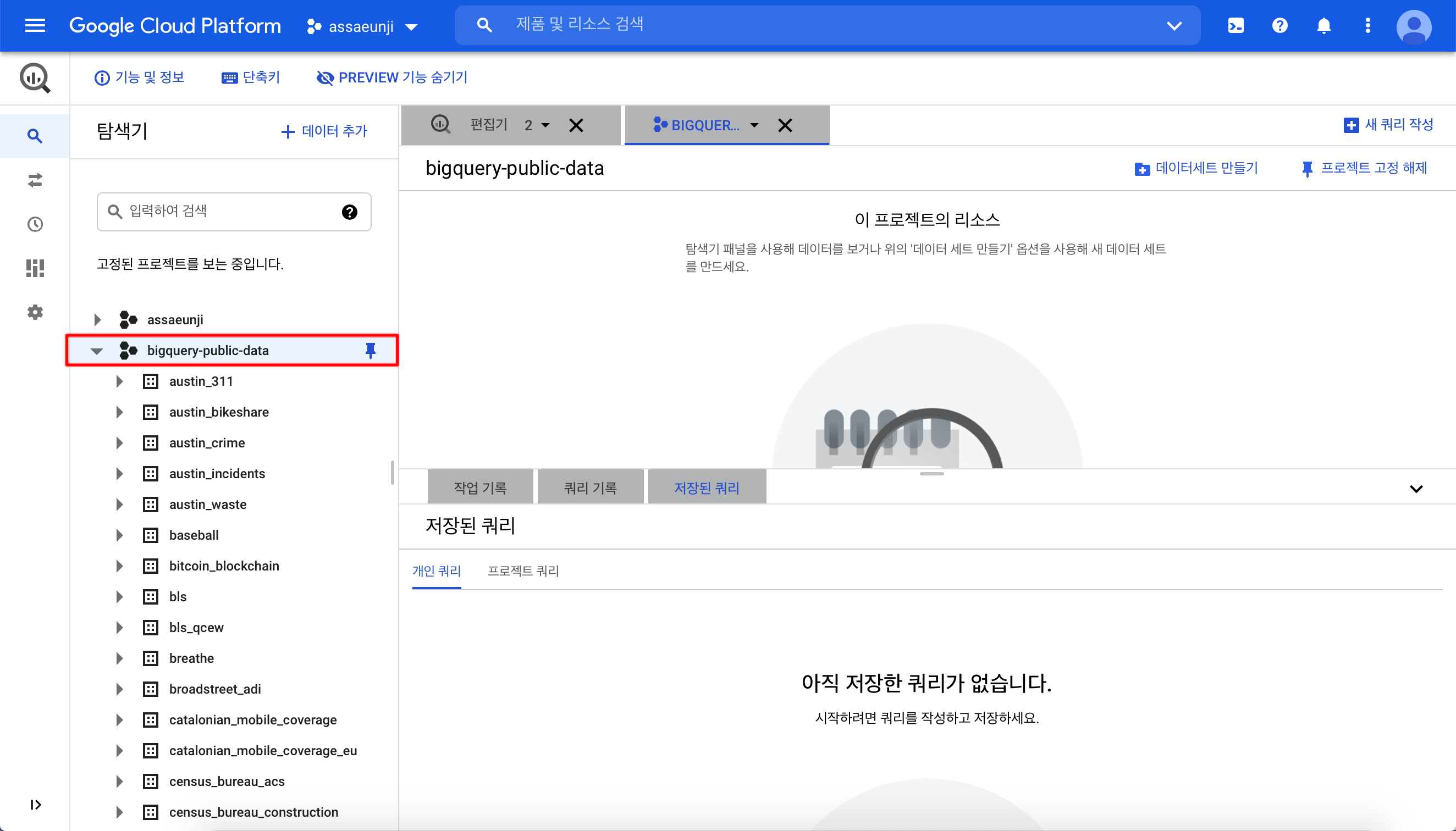
모델 저장할 데이터세트 만들기
BigQuery로 K-평균 클러스터링 모델을 만드려면 이전에 모델을 저장할 데이터세트를 따로 만들어야 합니다. 이를 위해 다시 탐색기 창에서 프로젝트 ID 명을 가진 DB를 클릭한 후 (제 경우는 assaeunji) 우측의 데이터세트 만들기를 클릭합니다.
다음과 같이
- 데이터세트 ID에 bqml_tutorial,
- 데이터 위치에서 유럽 연합(EU)을 선택합니다. 런던 자전거 공유 공개 데이터세트는 EU 멀티 리전 위치에 저장되기 때문에 데이터세트도 같은 위치에 있어야 합니다.
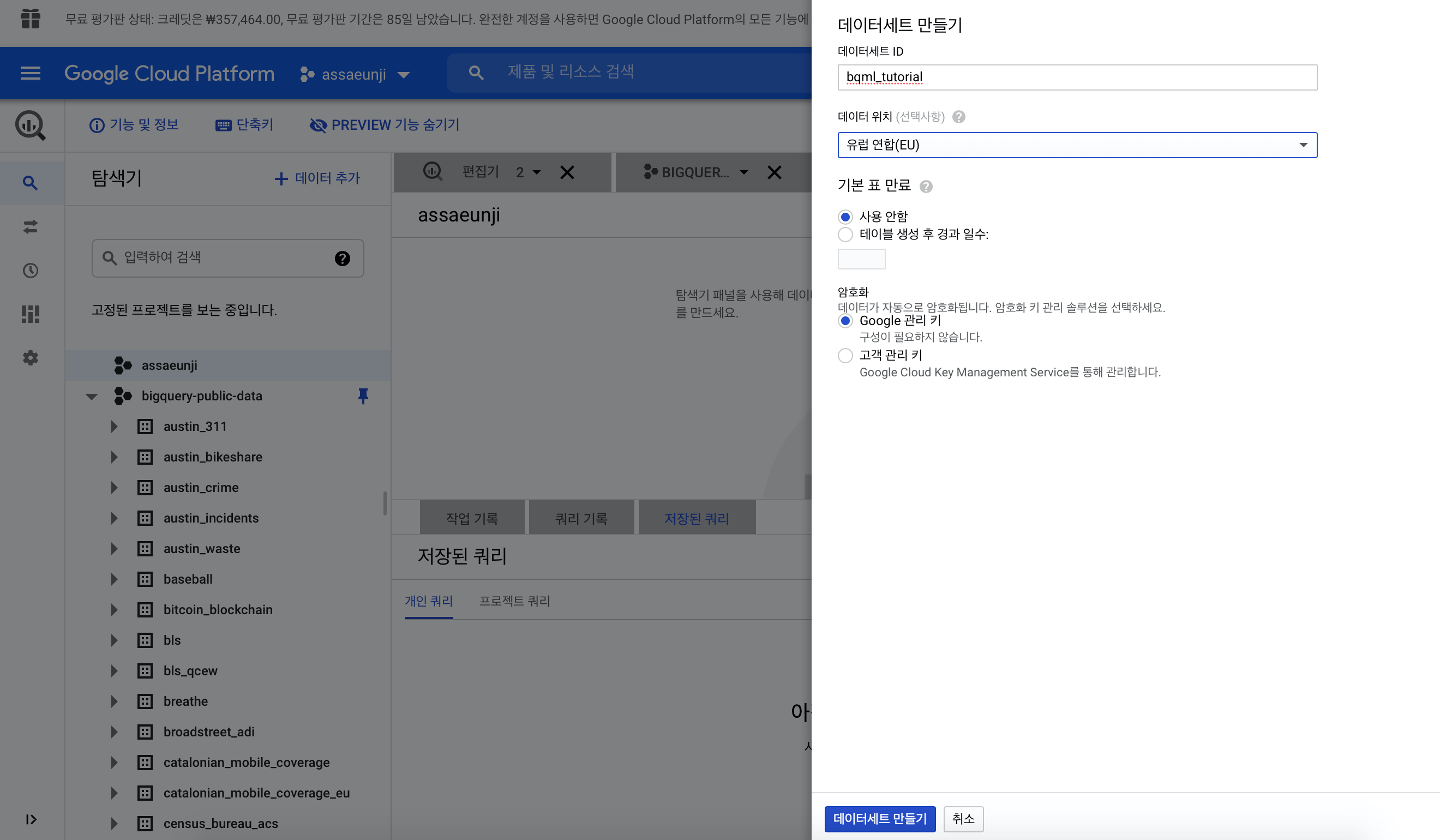
다른 기본 설정은 그대로 두고 데이터세트 만들기를 클릭합니다.
데이터 톺아보기
저희가 사용할 데이터는 런던 자전거 데이터로, 다음 속성을 이용해 자전거 정거장을 클러스터링하는 것이 목표입니다.
- 대여 기간
- 일일 대여 횟수
- 도심에서의 거리
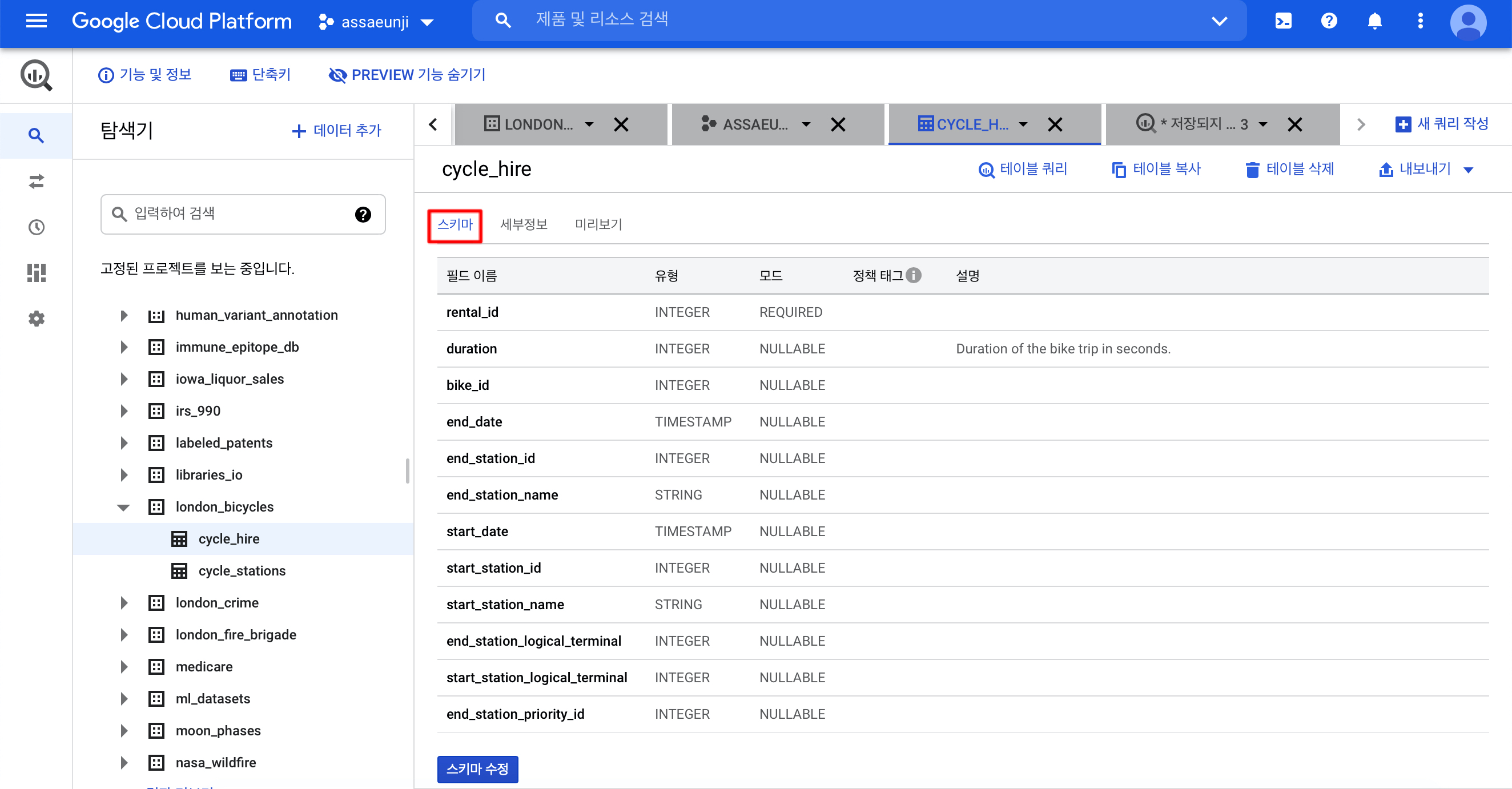
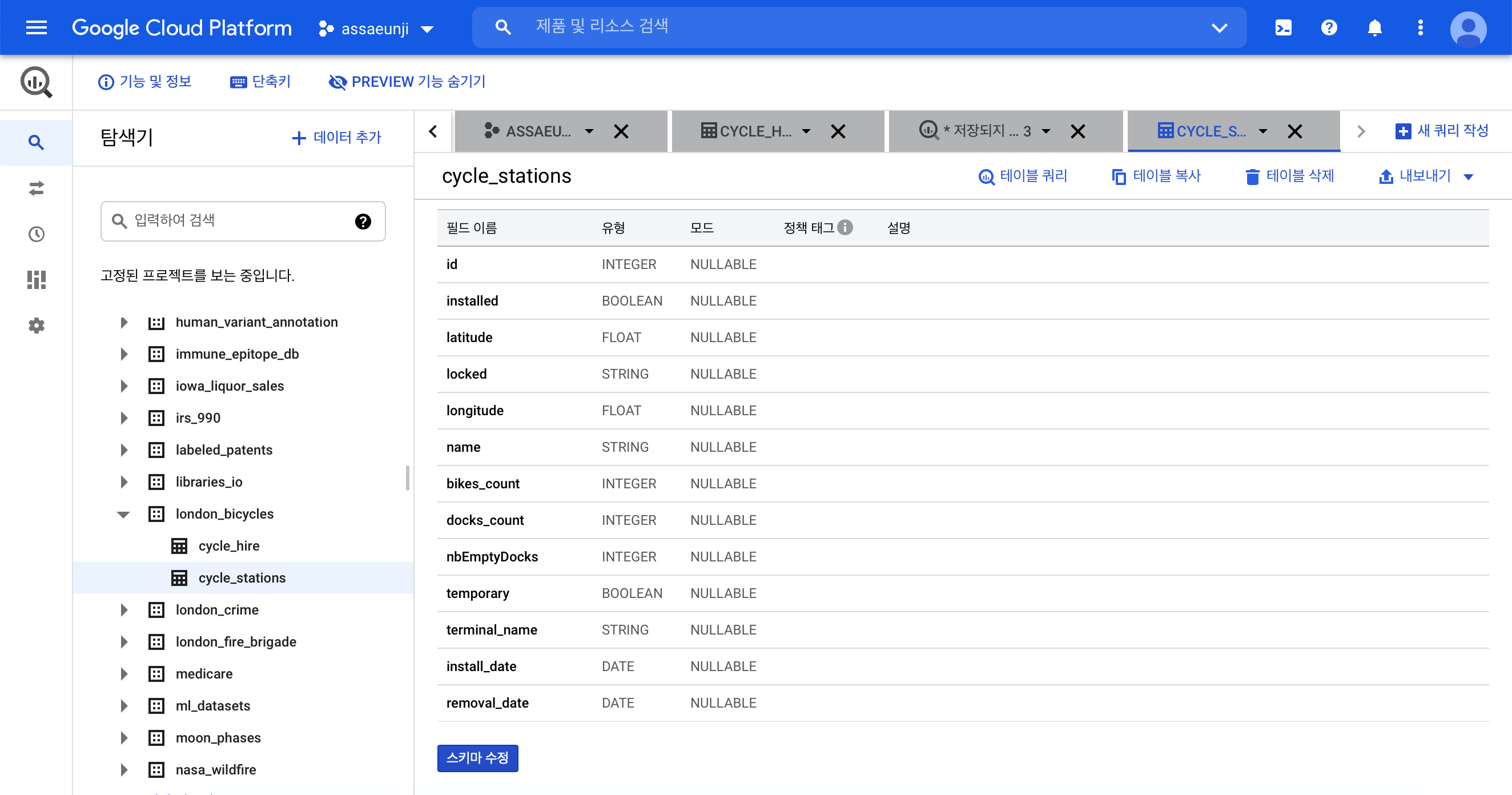
london_bicycles 데이터세트는 두 개의 테이블을 가지고 있습니다. 아래 그림처럼 해당 테이블의 스키마를 클릭하면 어떤 열을 갖고 있는 테이블인지 알 수 있습니다.
-
cycle_hire: 대여할 때마다 기록되는 대여 정보 테이블입니다. 대여 ID (rental_id)와 자전거 ID(bike_ID)로 key를 갖고 있고, 각 대여 건마다 대여 시간 (duration),
출발점과 종착점의 정보들이 나와있습니다.
-
cycle_stations: 자전거 대여소에 대한 정보를 담고 있는 테이블입니다. 대여소 ID (id)의 위도 (latitude), 경도 (longitude), 자전거 보유 현황 (bikes_count) 등의 정보를 담고 있네요.
-
이 두 테이블에 JOIN KEY가 되는 건
cycle_stations의대여소 ID와cycle_hire의출발점 혹은 종착점 id가 됩니다.
클러스터링에 사용할 변수 집계하기
저희가 정거장을 클러스터링할 때 사용할 변수는 대여 기간, 일일 대여 횟수, 도심에서의 거리입니다. 이를 집계하는 쿼리는 다음과 같습니다.
1 | with hs as ( |
이 쿼리를 쿼리 편집기 텍스트 영역에 입력하고 실행을 클릭합니다.
해당 쿼리는 크게 세 부분으로 나눌 수 있습니다.
- 임시 테이블
hs만들기 - 임시 테이블
stationstats만들기 stationstats정보 불러오기
엄연히 말하면 with절 안에 쓰인 hs와 stationstats는 from절에 쓰일 서브 쿼리를 먼저 정의한 것인데,
쉽게 말하면 이 둘은 임시 테이블의 역할을 하고 있기 때문에 임시 테이블이라 하겠습니다.
즉 with hs as (쿼리1)로 쿼리 1의 실행 결과가 hs라는 임시 테이블에 저장되고, stationstats as (쿼리2) 쿼리 2의 실행 결과가 stationstats라는 임시 테이블에 저장되어서 이를 with절과 함께 쿼리를 실행하면 데이터를 조회할 수 있습니다.
만약 해당 방법을 사용하지 않고, 서브 쿼리 형태 그대로 코드를 짠다면 다음과 같을 것입니다.
1 | select * |
위 코드는 이중 서브 쿼리 때문에 가독성이 떨어집니다. 그래서 with문을 이용해서 서브쿼리를 위에서 먼저 정의해주는 것이죠~!
자, 그럼 각 임시 테이블을 생성하는 쿼리에 대해 알아봅시다. 먼저 hs라는 테이블을 만드는 쿼리는 다음과 같습니다.
1 | select |
cycle_hire와cycle_stations를 join 하는데 key가 되는 컬럼은cycle_hire의start_station_id와cycle_stations의id입니다. 여기서 조인의 형태는 내부 조인 (inner join)으로 inner 단어를 생략할 수 있다 하네요. 이렇게 조인해서 공통이 되는 정거장들의 대여 정보만 가져오게 됩니다.- 또한 where 조건 절에 대여 시작일이 2015년 한 해인 것만 가져오도록 하고 있습니다.
hs의 컬럼 정보는 다음과 같습니다.
- 첫 번째 컬럼은 공통이 되는 정거장 이름 (
station_name)입니다. - 두 번째 컬럼은 주중/ 주말을 구분하는
isweekday라는 컬럼입니다.cycle_hire의 대여 시작 시간에서 요일을 추출해서 7 (토요일), 1 (일요일)의 값을 가지면 “weekend” (주말)라는 값을 갖고, 그 외 주중이라면 “weekday” (주중)이라는 값을 갖도록 합니다. - 세 번째 컬럼은
cycle_hire의 대여 시간을 나타내는duration컬럼입니다. - 네 번째 컬럼은 도시에서의 거리를 나타내는
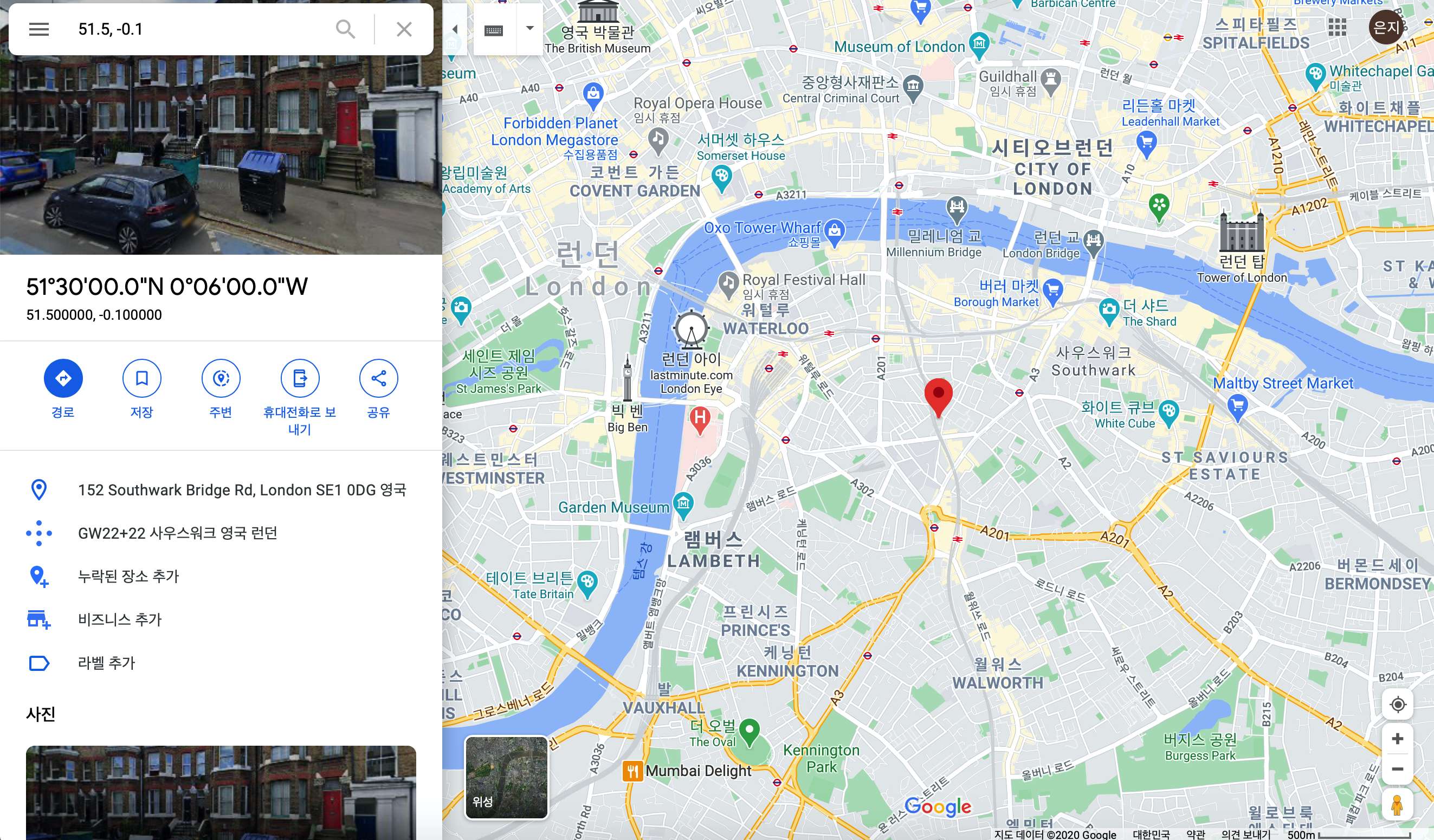
distnace_from_city_center컬럼인데요. 먼저st_geogpoint(경도, 위도)라는 BigQuery의 지리 함수를 이용해서 해당 대여소의 위치를 반환해주고,st_geogpoint(-0.1, 51.5)라는 지점과 대여소 간의 거리를 계산해주는st_distance (지역1, 지역2)함수를 사용합니다. 이 함수는 두 지역 간의 최단 거리를 미터 단위로 계산해줍니다. 따라서 이를 1000으로 나눠서 킬로미터 단위로 만든 것이 해당 컬럼입니다. 여담으로 st_geogpoint(-0.1, 51.5)에 해당하는 지역이 어딜까 구글 지도에서 찍어보니 사우스워크 영국 런던라는 곳이 찍히네요!
이에 해당하는 쿼리만 실행하면 hs테이블의 형태를 볼 수 있습니다.
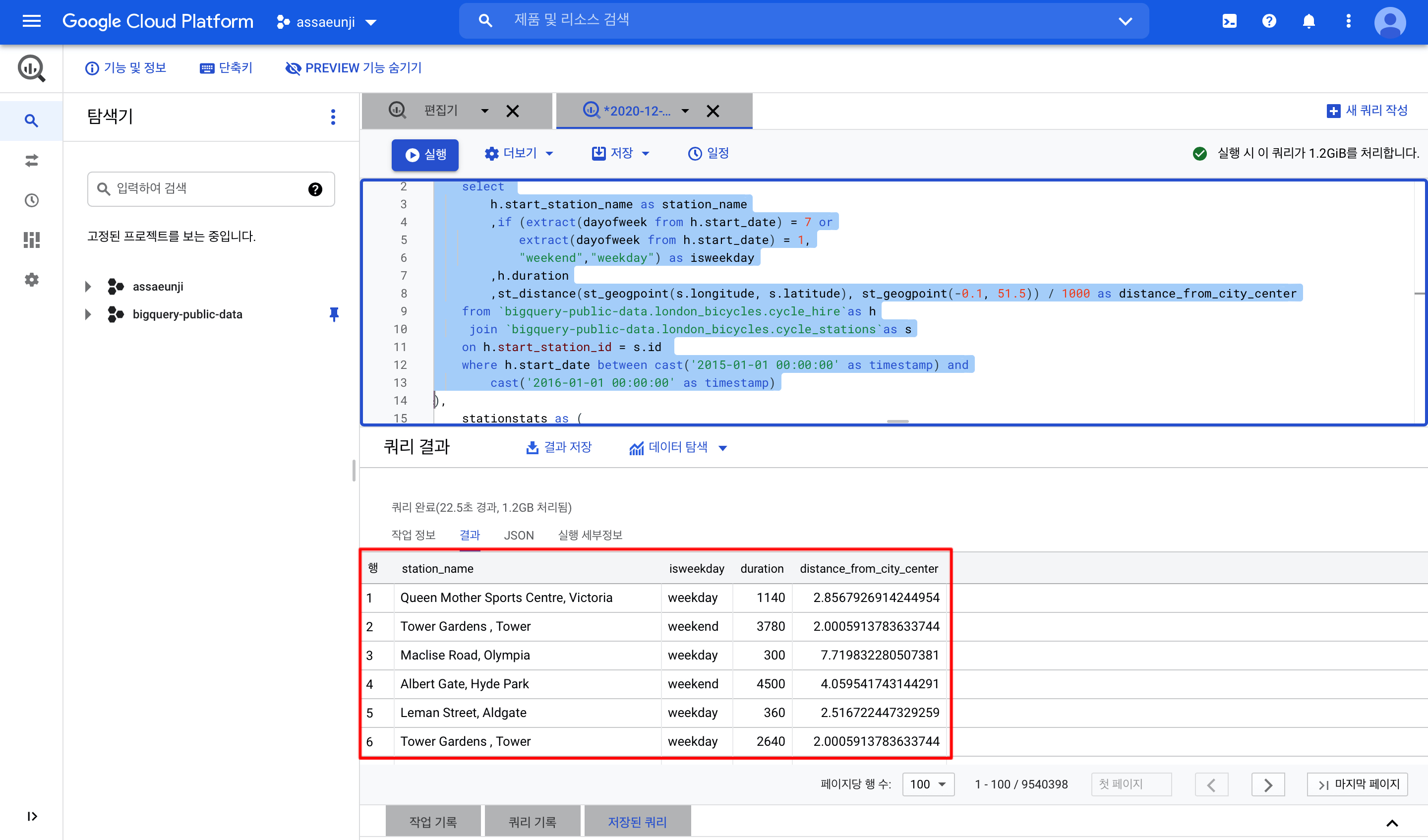
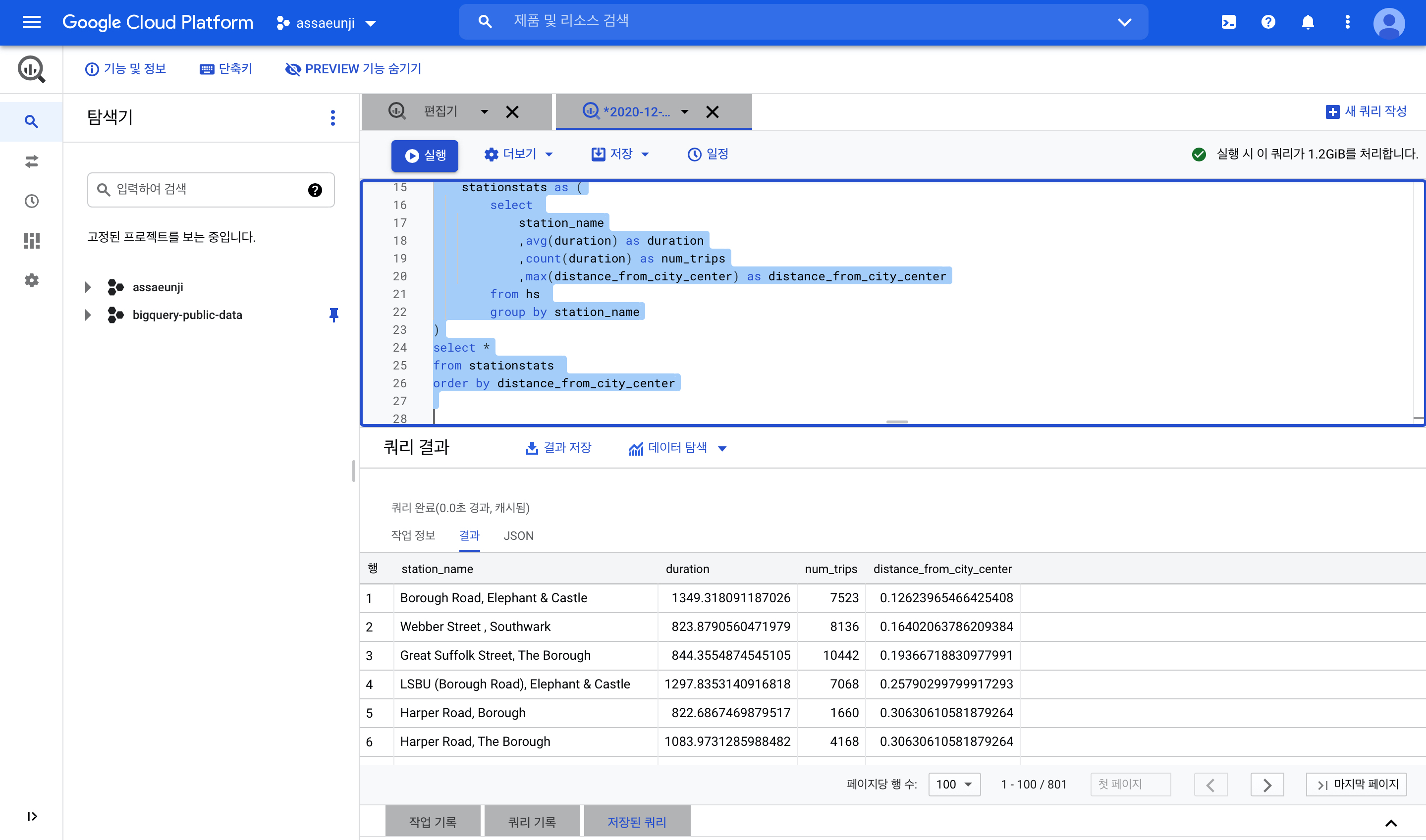
자, 그럼 hs에서 2015년 한 해 동안의 대여소 정보를 가져왔습니다. 대여를 할 때마다 행이 생성되기 때문에, 이를 대여소마다 한 행만 남도록 집계해주는 테이블이 필요합니다. 이를 stationstats라는 임시테이블에서 집계합니다.
1 | select |
이 쿼리를 실행하면 hs가 저장된 테이블이 아니라 임시 테이블이다 보니 오류가 생깁니다. 따라서 위에서 소개한 쿼리 전체를 한꺼번에 돌려야 오류를 방지할 수 있습니다. 일단 편의를 위해 해당 쿼리로만 설명을 드리겠습니다.
hs테이블에서 대여소 (station_name) 이름별로 group by를 합니다. 이를 통해 대여소마다 한 행만 남도록 집계할 수 있습니다.- 두번째 컬럼
avg(duration)는 대여소 별 평균 대여 시간을 의미합니다. - 세번째 컬럼
count(duration)는 대여소 별 1년 간 총 대여 횟수를 의미합니다. - 두번째 컬럼
max(distance_from_city_center)는 대여소에서 시내에서 떨어진 거리의 최댓값입니다. 어차피 대여소의 위치와 도시의 위치는 정해져있으니max를 쓰든min을 쓰든 같은 값이 도출됩니다. 그럼 굳이 왜max를 쓰느냐? group by 절에 지정하지 않은 컬럼을 출력하고 싶다면, 어떻게든 집계 함수를 통해 표현해야하기 때문입니다.
이렇게 도출된 테이블은 다음과 같습니다.
k-평균 모델 만들기
이제 데이터를 살펴봤으니 다음 단계는 k-평균 모델을 만드는 것입니다.
create model 문을 model_type = 'kmeans’라는 옵션과 함께 사용해 k-평균 모델을 만들고 학습시킬 수 있습니다. 다음 쿼리는 create model` 문을 이전 쿼리에 추가하고 데이터에서 id 필드를 삭제합니다.
1 | create or replace model |
이전 쿼리와 위 쿼리가 다른 부분은 두 가지입니다.
먼저, 이전 쿼리 위에 k-평균 모델을 생성하는 문을 넣었습니다.
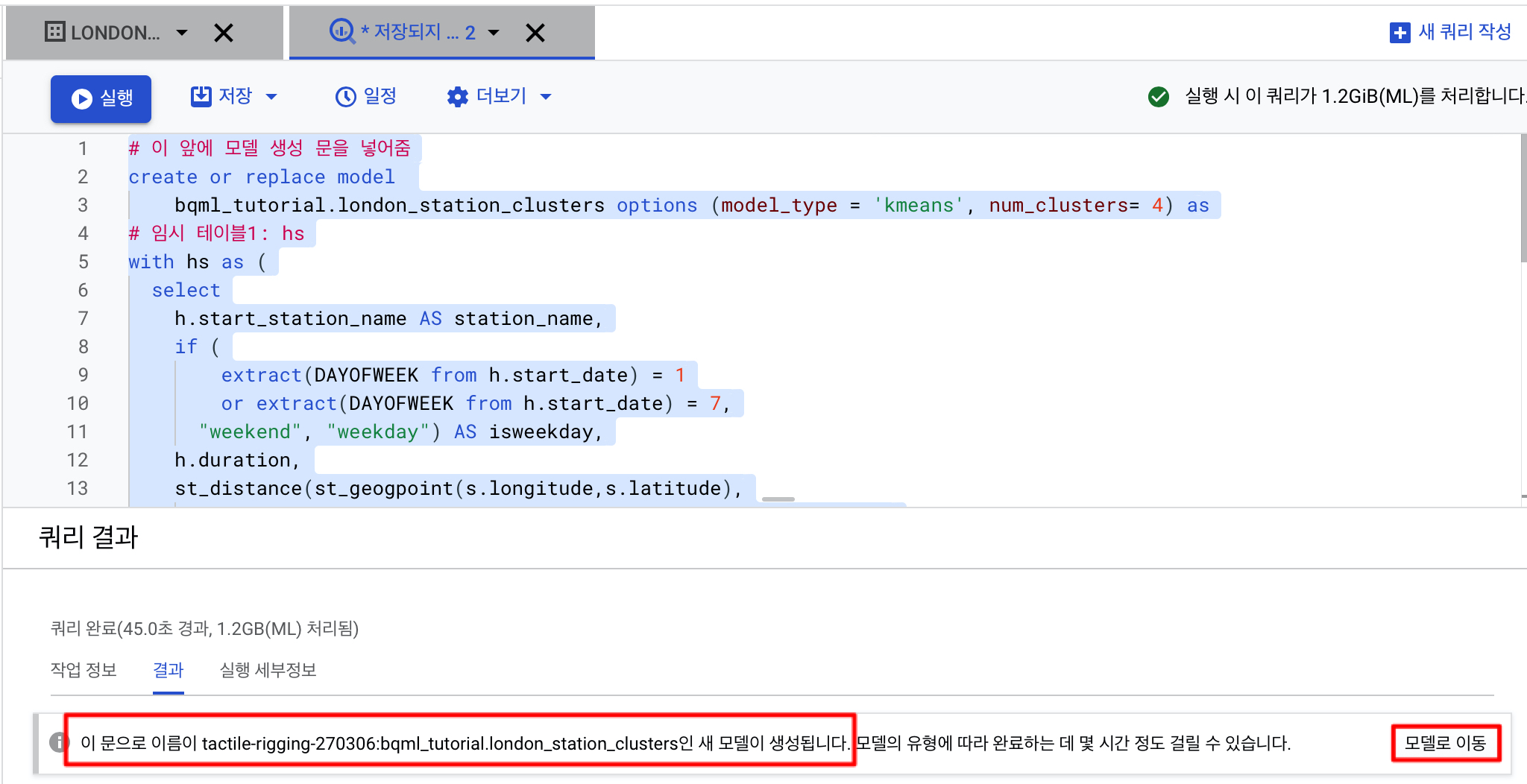
모델을 저장하는 곳은 모델 저장할 데이터세트 만들기파트에서 만들었던 bqml_tutorial 데이터 세트입니다. 여기에 london_station_clusters라는 이름으로 모델 결과가 저장됩니다.
1 | create or replace model |
두번째로 stationstats를 정의할 때 group by 절에 isweekday라는 변수를 넣고, select 절에 except (station_name, isweekday)를 추가했습니다.
- 이렇게 한 이유는 추측상 일단 주중/ 주말마다 대여 시간이나 횟수가 차이가 나기 때문에 정거장 & 주중/주말 별로 어떻게 클러스터링이 되는지를 보고자 한 것 같습니다.
- 또한
except(컬럼명)을 쓰면 해당 컬럼만 제외하고 불러오는 것을 의미합니다. k-평균에 들어갈 변수는 3개 (duration, num_trips, distance_from_city_center)이기 때문에 이 station_name, isweekday 두 컬럼은 제외하고 불러오는 것입니다.
쿼리가 완료되면 다음과 같은 안내문이 뜹니다. 그럼 옆의 모델로 이동버튼을 클릭해봅니다.
그러면 bqml_tutorial데이터 세트에 생성한 london_station_clusters 모델에 대한 세부 정보를 볼 수 있습니다.
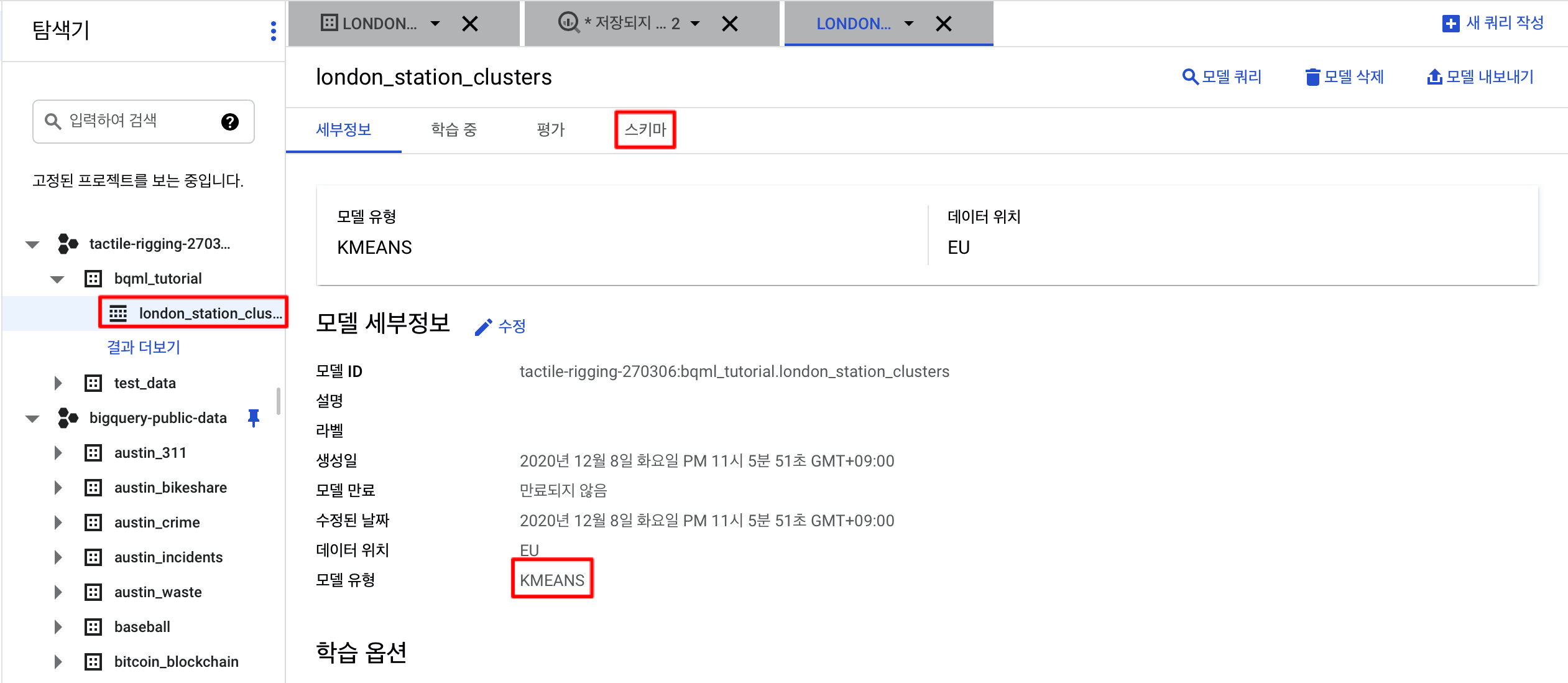
위와 같이 스키마를 클릭하면 duration, num_trips, distance_from_city_center의 컬럼을 가지고 모형을 수행했을을 알 수 있습니다.
평가를 클릭하면 k-평균 모델로 식별된 클러스터가 시각화되어 표시됩니다.
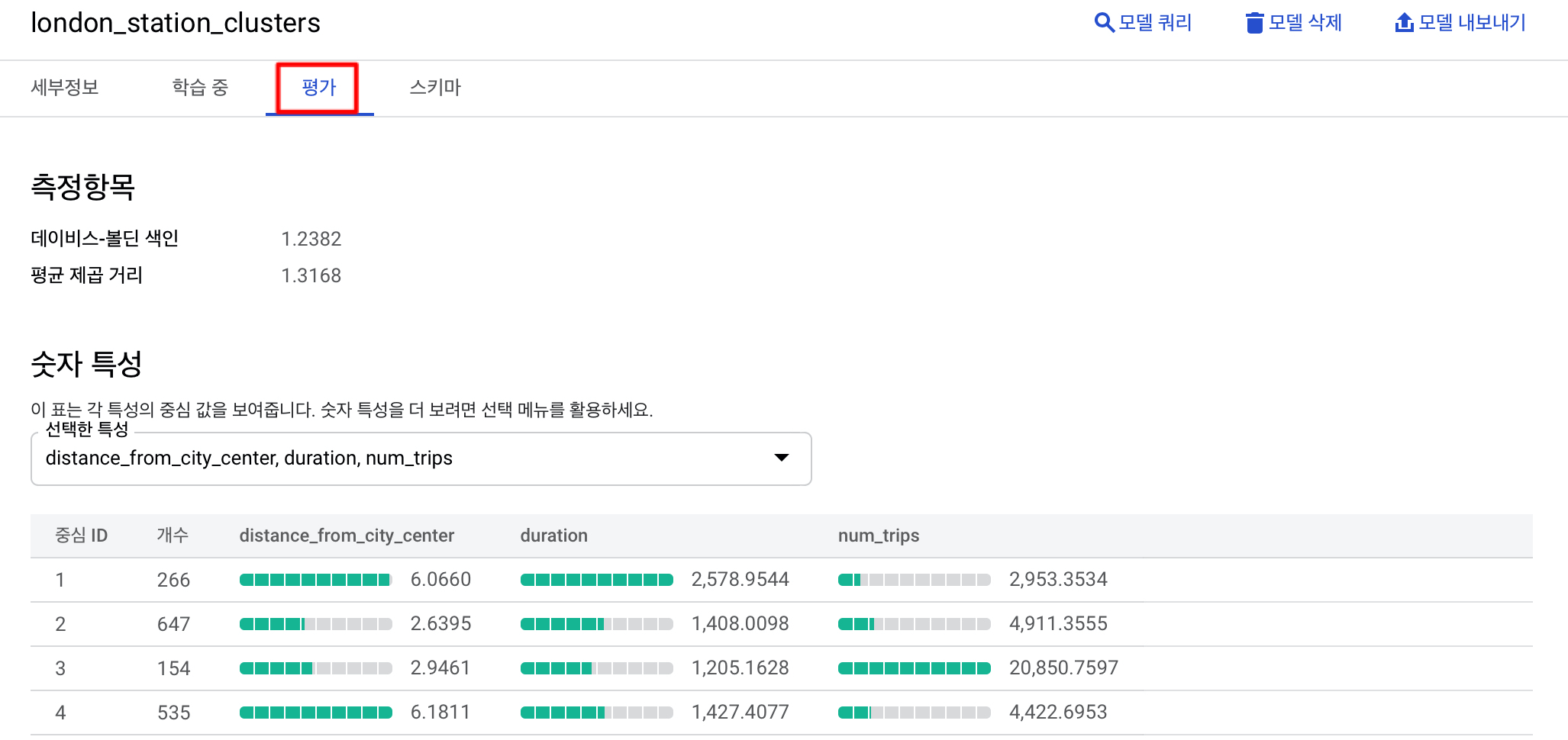
create model문에 num_clusters를 4개로 두었기 때문에 4개의 centroid (중심)을 가진 클러스터가 나왔고, 이 클러스터 각각에 대한 정보를 확인하실 수 있습니다.
ml.predict 함수를 사용해 정거장의 클러스터 예측
특정 정거장이 속한 클러스터를 식별하기 위해 ml.predict 함수를 사용합니다.
1 | ## 모델 평가하기 |
위에서 ml.predict 함수는 두 개의 변수를 갖습니다.
- 첫 번째는 생성한 모델
- 두 번째는 예측 대상 데이터입니다.
except(nearest_centroids_distance)를 적어주지 않으면 다음과 같이 각 4개의 centroid로부터 해당 데이터까지의 거리를 모두 계산해줍니다.

따라서 예측한 클러스터만 보기 위해서 except(nearest_centroids_distance)를 적어주면 최종 결과는 다음과 같습니다.
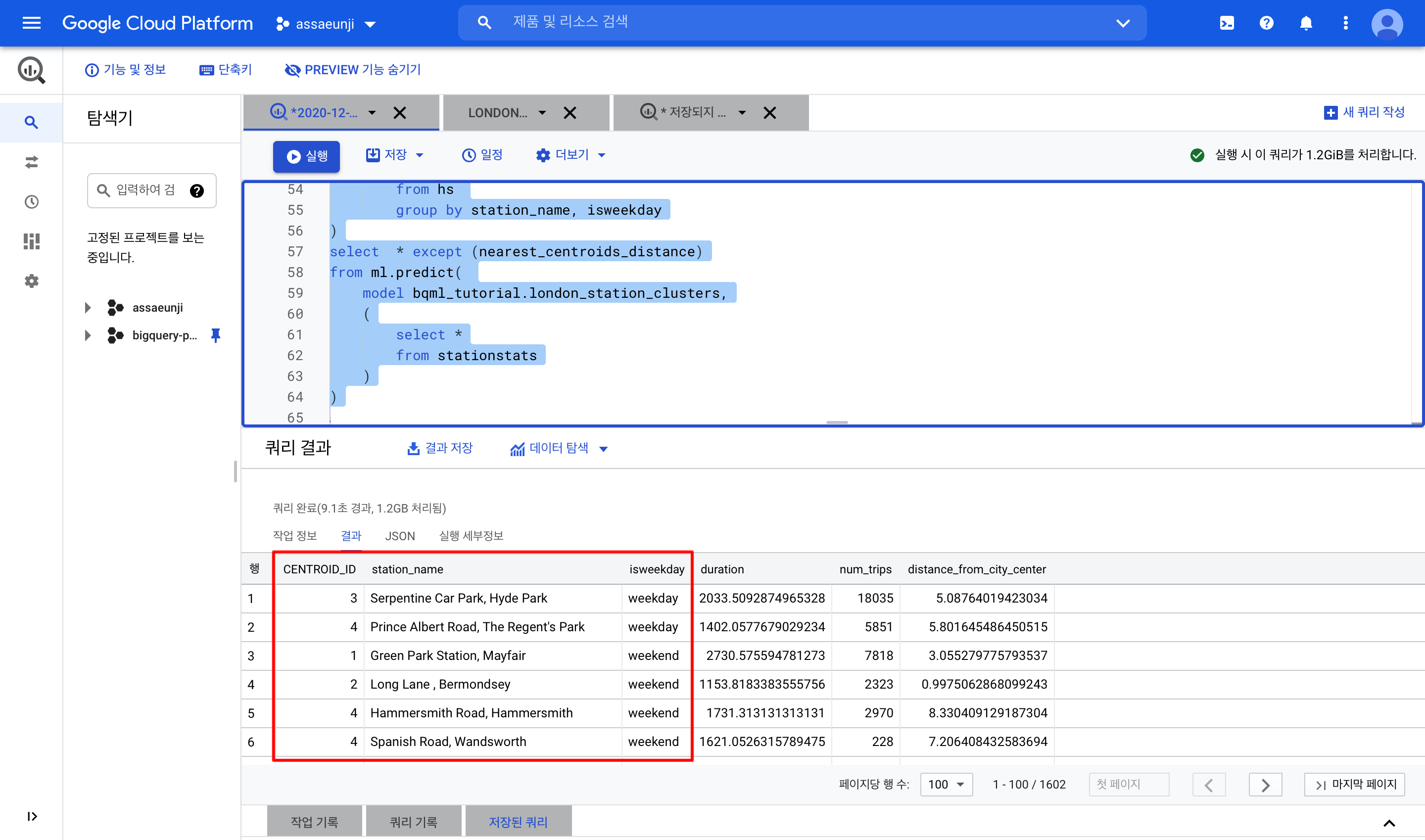
각 대여소마다 어떤 클러스터에 속해있는지를 centroid_id를 통해 알 수 있습니다.
모델을 사용해 데이터에 근거한 의사 결정 내리기
자 다시 이 그림을 봅시다.
- 클러스터 #1은 도심에서 멀고, 평균 대여 시간도 긴 대여소를 보여줍니다.
- 클러스터 #2도 도심에서 가깝지만, 상대적으로 덜 혼잡한 교외 대여소입니다.
- 클러스터 #3은 대여 횟수가 압도적으로 많고, 도시에서 가까운 인기 있는 대여소입니다.
- 클러스터 #4는 도심에서 멀지만 클러스터 #1에 비해 대여 시간이 짧습니다.
이러한 결과를 바탕으로 데이터를 사용해 정보에 근거한 의사결정을 내릴 수 있습니다. 예를 들면
- 일부 정거장에 경주용 자전거를 비치하는 경우를 가정해보겠습니다. 클러스터 #1이 도심에서 멀리 떨어져 있어 운행 거리가 가장 긴 대여소 그룹이기 때문에 경주용 자전거를 위한 후보지로 적합할 수 있습니다.
- 런던 도심의 자전거 대여 패턴을 분석하는 경우, 도심과 가깝고 대여 횟수도 많은 클러스터 #3에 속한 정거장을 먼저 분석해볼 수도 있습니다.
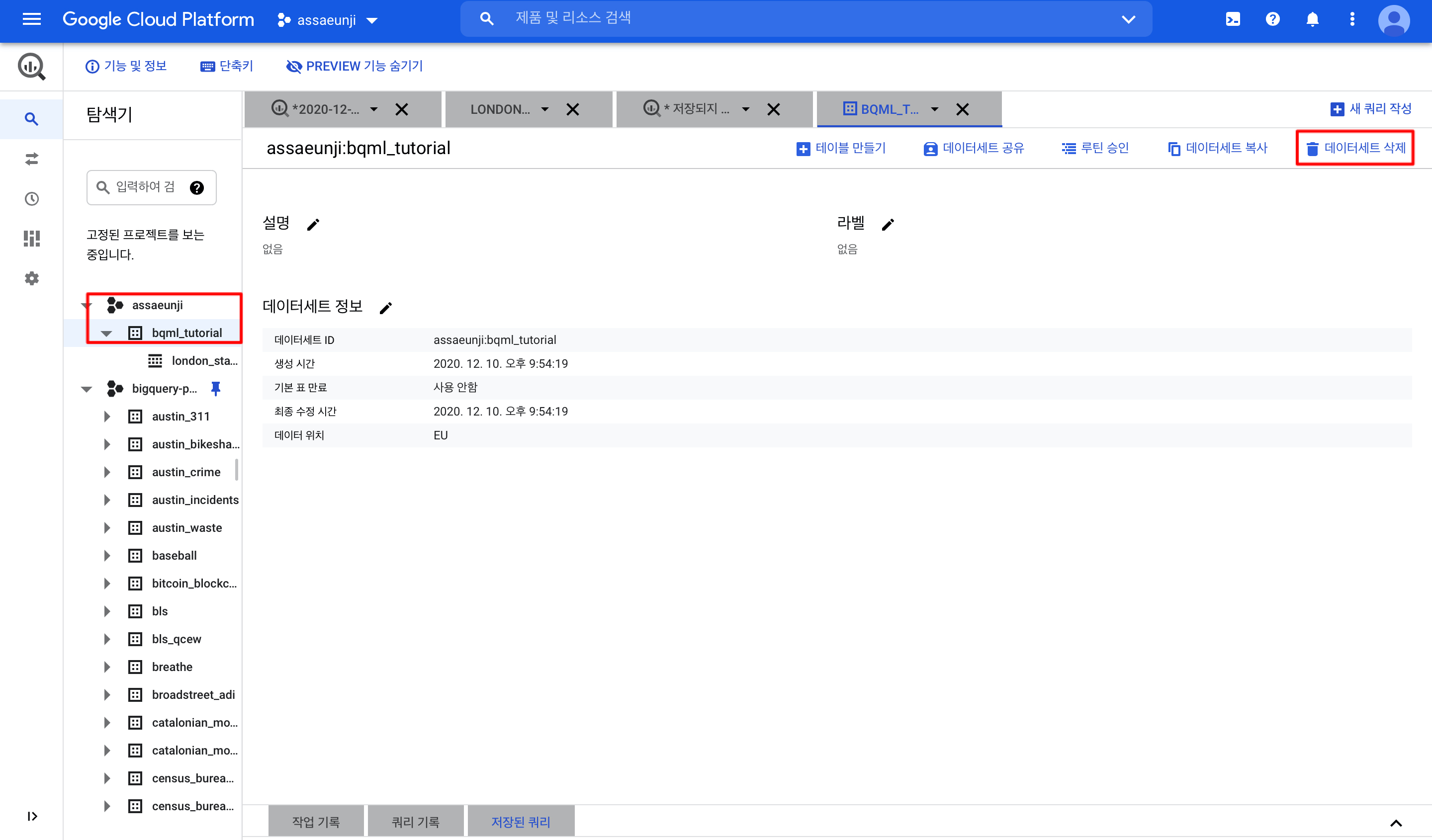
삭제
이 가이드에서 사용한 리소스 비용이 GCP 계정에 청구되지 않도록 데이터세트를 삭제하는 것이 좋습니다.
이를 위해 다시 탐색기에 들어가 해당 데이터세트를 클릭하고 우측에 있는 데이터세트 삭제를 클릭하면 데이터가 삭제됩니다.