
라떼 시리즈 (2): 공수를 줄이는 Summary 테이블 쌓는 법
- 이번엔 라떼 시리즈 (1): 회사에서 꽤나 괜찮은 주니어가 되려면 에 이어 더 구체적인 라떼로 돌아왔습니다.
- 저는 특히 태블로로 데이터를 시각화하기 위해 Summary 용 테이블을 쌓는 경우가 많은데요. 처음 대시보드를 만들 땐 제가 쌓은 Summary 테이블이 어떻게 태블로에 구현되는지 상상하지 못한 채 쌓아 고생했던 경험이 있습니다.
- 그런데 선배가 맡던 테이블을 관리하게 되면서, 공수가 적게 들도록 Summary 테이블을 쌓는 방법에 대해 이해하게 되었습니다. 따라서 이 꿀팁을 공유하고자 포스팅을 씁니다! (선배님 짱!)
Summary 테이블이란?
Summary 테이블은 말 그대로 요약 테이블로, 어떤 Raw 테이블에서 필요한 정보만 뽑아 집계한 테이블을 의미합니다.
보통 대시보드에서 일, 주, 월별로 어떤 사건이 일어났는지를 집계하게 되는데요.
예를 들어, 넷플릭스 관련 Summary 테이블을 쌓는다고 가정하면
- 일/주/월 별 넷플릭스에서 1개 이상의 영화를 시청한 고객 수
- 일/주/월 별 넷플릭스에 접속한 로그 수
- 일별 client IP 별 동시 접속자 수
등의 지표를 바탕으로 넷플릭스의 active 유저의 규모, 허들, 어뷰징 등 다양한 주제로 풀어 대시보드로 시각화할 수 있겠죠.
태블로에서 대시보드를 시각화할 땐 저는 아래와 같은 과정을 거칩니다.
- Spark 환경에서 로그를 불러와 Summary 테이블을 적재한다.
- 1번의 코드를 일/주/월 등 원하는 주기로 테이블을 적재하도록 Airflow를 사용한다.
- Summary 테이블이 있는 DB 주소를 태블로와 연결환다.
- 태블로에서 시각화해 Web 서버와 연결한다.
물론 1번의 과정에서 Summary 테이브를 집계하지 않고 Raw 테이블에서 SQL 쿼리를 직접 사용하여 Summary 테이블 (GROUP BY 쿼리 사용)을 만드는 것도 가능하나,
경험상 1만 건 이상 넘어가는 테이블을 불러오면 로딩 시간이 길어 활용성이 적었습니다.
그렇기 때문에 빠르게 데이터를 불러오고 시각화를 하기 위해서 Raw 테이블이 아닌 Summary 테이블을 애용하게 됩니다.
공수를 어떻게 줄인다는 거죠?
그러면 적당히 Raw 데이터에서 Summary 용 테이블을 만들고 적재하면 될텐데 공수를 어떻게 줄인다는 것일까요?
제 기준은
- 데이터 집계가 잘못되었을 때
- 새로운 컬럼이 추가되었을 때
- 컬럼의 값이 변경 / 추가될 때
테이블을 새로 만들 필요없이 UPDATE 문 만으로도 테이블을 갱신할 수 있거나 혹은 Airflow에서 재처리 없이 자동 반영되는 구조라면 공수가 적다고 생각합니다.
우선 테이블을 새로 만드는 건 생각보다 매우 귀찮은 작업입니다.
기존의 Summary 테이블이 A, 새로 만들 테이블이 B라고 하면
- A의 데이터를 B로 옮겨줘야하고 (이걸 소급 적용한다고 말합니다)
- 쿼리 효율화를 위해 B에도 인덱스를 걸어줘야하고
- B의 이름도 새로 지어주고, B 테이블을 쌓는 코드에서도 적재하는 테이블 주소를 B로 변경해주어야 합니다. 혹 A 테이블 명을 그대로 사용하고자 한다면 새로 지을 테이블 B에 1, 2번 작업을 끝낸 후 A를 지우고 B의 이름을 A와 같이 변경해줘야 합니다.
또한 Airflow에서 재처리하는 것도 시간이 꽤 걸리는 작업일 수도 있습니다.
만일 집계가 잘못되어 재처리해야하는 일자가 1년이 넘어간다면 하루 당 10분만 걸린다고 해도 3,650분 = 61시간 = 2.5일 정도 소요되는 작업입니다.
그래서 공수를 줄이는 Summary 테이블을 잘 만들면 이 두 작업 없이
UPDATE문 만으로 10분 안에 데이터 재처리가 가능해지고- 테이블을 새로 만들 필요 없이 코드 수정만 하면 바로 대시보드에 반영되도록 할 수 있습니다.
공수를 줄이는 Summary 테이블을 만드는 법
위에서 언급한 세 가지 상황에 대해 아래와 같이 솔루션을 정리했습니다.
- 데이터 집계가 잘못되었을 때, Airflow에서 재처리를 하지 않아도 되도록 Raw 테이블도 쌓자.
- 새로운 컬럼이 추가되었을 때, 테이블 구조를 건드리지 않도록 WIDE 형태 대신 LONG 형태로 쌓자.
- 컬럼의 값이 변경/추가되었을 때, Airflow에서 재처리를 하지 않아도 되도록 ID 컬럼을 남기자.
구체적으로 알아볼까요~?
첫째, Raw 테이블을 쌓자. 그러면 재처리가 쉬울 것이다!
데이터 집계가 잘못되는 경우는 보통 대시보드를 오픈하기 전이나 직후인 경우가 많습니다.
저는 기획팀에서 대시보드 기획안을 전달주시면 저희 팀에서 데이터를 집계하고 시각화해 리포트 링크를 전달드렸던 경험이 많은데요.
기획팀에서 의도했던 지표와 제가 집계한 지표의 의미 차이가 있을 때, 이 싱크를 맞추는 과정에서 집계를 다시 하는 과정이 필요했습니다.
이건 제가 많은 환경을 접해보지 못한 것일 수도 있지만, 경험 상 Airflow로 데이터를 재처리하는 것보다
DB 환경에서 Raw 테이블을 직접 땡겨와서 Summary 테이블을 UPDATE 해주는 방식이 더 빨랐기 때문에 Raw 테이블을 쌓았습니다.
또한 실제 집계한 지표 값이 맞는지 Raw 데이터를 직접 요청하는 경우도 있기 때문에 검증 차원에서 Raw 테이블을 쌓는 것이 좋습니다.
Raw 테이블을 쌓은 후 Summary 테이블에 잘못된 집계 값을 수정하고자 한다면 JOIN 과 UPDATE 문으로도 데이터를 수정할 수 있습니다.
예를 들어,
- 2022년 9월 1일부터의 Summary 데이터가 잘못되었다면
- Summary 테이블 (
#summary_table)과 Raw 테이블 (#raw_table)을 집계한 결과를INNER JOIN하고 - 잘못된 Summary 테이블의 값을 수정된 값으로
UPDATE해주면 됩니다.
1 | -- SQL Server 쿼리 기준 |
둘째, WIDE가 아닌 LONG 형태로 쌓자. 새로운 지표가 생겨도 두려움이 없을 것이니…
WIDE와 LONG 테이블의 차이를 아시나요?
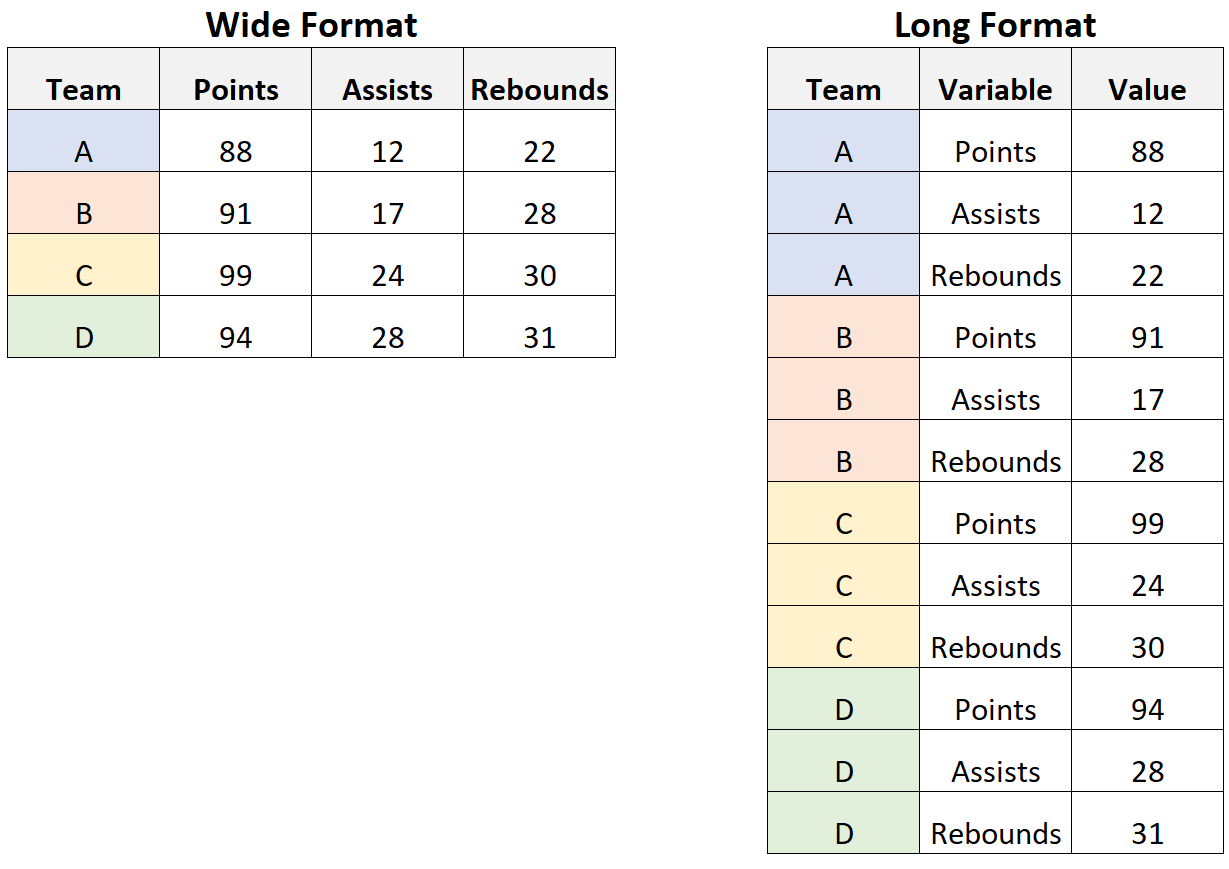
- WIDE 형태는 관심 있는 지표 이름이 컬럼으로 넓게 붙고, 지표의 값이 각 테이블의 값으로 붙는 경우를
- LONG 형태는 지표 이름이 하나의 컬럼 안에 길게 붙는 경우를 의미합니다.
예를 들어, 한 날짜에 보고 싶은 지표가 3개라면 WIDE 테이블은 행이 1개면 되지만, LONG 테이블은 행이 3개인 셈입니다.
얼핏보면 WIDE 테이블이 더 직관적이고 태블로에서 구현하고 싶은 최종 형태이기 때문에 더 좋아보일 수 있습니다.
그러나, 테이블의 행을 늘리는 것은 쉽지만 열을 늘리는 것은 어렵습니다. 테이블에 새로운 열을 추가한다는 것은 스키마가 변경되는 작업이기 때문이죠.
따라서 WIDE 테이블로 Summary 테이블을 말고 나서 새로운 지표가 추가될 경우, 테이블 구조를 수동으로 변경해주어야 하기 때문에 공수가 많이 듭니다.
또한, 태블로에서 구현할 때에도 WIDE 형태라면 “열” 부분에 원하는 지표들을 일일이 드래그해서 넣어줘야하는 공수가 있는 반면,
LONG 형태라면 “열” 부분에 지표 명 컬럼 (위 예시에서는 Variable)만 넣어주면 되기 때문에 지표가 10개 이상 있다면 LONG 이 훨씬 더 이득입니다 😃
이와 더불어 대시보드에서 일/주/월 지표를 구현할 때도 테이블을 3개 만드는 것보단 1개 안에 일/주/월을 구분하는 컬럼을 넣어주고 LONG 형태로 쌓는 것이 관리 상 이점이 있습니다.
셋째, 서비스를 구분하는 ID 컬럼을 쌓고, Dimension 테이블과 INNER JOIN 대신 LEFT JOIN을 하자.
이 부분은 제가 가장 강조하고 싶은 부분입니다!
예전에는 Summary 테이블에서 서비스를 구분하는 ID 컬럼은 제외하고 서비스 명에 따른 지표 값만 적재하는 경우가 종종 있었습니다.
제 회사의 경우, 여러 게임의 지표를 한 번에 보고 싶은 니즈가 종종 있는데요.
- 로그에서는 보통 게임 ID와 유저 ID에 따라 행동 지표 (ex. 로그인, 구매, 충전 등)가 적재되고
- 이를 Dimension 테이블 (게임 ID와 게임 명이 있는 테이블)과 조인해 게임 명을 가져오는 경우가 일반적이었습니다.
이렇게 게임 ID를 적재하지 않고 게임 명에 따른 지표 값만 적재했을 때의 문제는 게임 명이 변경될 경우, 일일이 업데이트를 쳐줘야 한다는 점입니다.
최근 실제로 이런 경험을 했어서 매우 공수가 많이 드는 작업임을 체감했는데요.
과거의 Summary 테이블은 Dimension 테이블과 조인할 key가 없기 때문에 이전 게임 명 -> 변경할 게임 명을 모두 UPDATE 쳤던 경험이 있습니다.
예를 들어, Summary 테이블에 서비스 ID (serviceid) 컬럼이 있는데 서비스 명이 변경되어서 소급 적용을 해줘야 하는 경우 아래처럼 한 번만 업데이트를 하면 되는데요.
1 | UPDATE A |
서비스 ID 컬럼이 없다면 아래처럼 변경된 서비스 명에 대해 모두 찾고 업데이트를 해줘야 합니다.
넷플릭스에서 특정 드라마에서 띄어쓰기가 없었는데 있는게 정식 명칭이기 때문에 Summary 테이블에도 반영을 해줘야 한다고 가정을 하면 아래처럼 업데이트 구문을 쭉~~ 써줘야 할 것입니다.
1 | UPDATE A |
언뜻 보면 쉬워보이지만 변경되는 서비스 명과 Summary 테이블이 1개일까요?
제 최근 경험을 비춰보면 12개의 서비스 명을 변경했고, 20개 정도의 테이블이 이에 영향을 받았습니다.
즉, 변경되는 서비스 명이 10개, Summary 테이블이 10개라면 100번을 업데이트해주어야 하는 비효율이 있는 것입니다. 또 수동 작업이기 때문에 UPDATE 되는 서비스 명도 잘못 적을 위험도 있습니다.
또한 INNER JOIN 대신 LEFT JOIN을 하는 것이 좋다고 하는 이유는 신규 서비스가 출시되었을 때 즉시 재처리가 가능하기 때문입니다.
신규 서비스가 출시되고 바로 다음 날 지표를 보고 싶은 니즈가 있다고 가정합시다.
- 로그는 신규 서비스의 런칭에 맞게 적재될 것이지만
- Dimension 테이블은 그렇지 않을 수도 있습니다. (특히 팀별로 수동으로 관리하는 Dimension 테이블)
그랬을 때 Dimension 테이블과 INNER JOIN을 한다면, 신규 서비스의 로그가 적재되었음에도 불구하고 Dimension 테이블에서는 없었기 때문에 Summary 테이블에 반영이 되지 않을 것입니다.
이에 비해 LEFT JOIN을 하고, 게임 명을 서비스 ID와 동일하게 넣는다면 추후 Airflow까지 가지 않고도 데이터를 업데이트해줄 수 있겠죠.
예를 들어 "수리남"이라는 넷플릭스 드라마가 나왔는데 아직 Dimension 테이블이 업데이트되지 않았다고 가정합시다.
그럴 경우 아래처럼 INNER JOIN을 한다면 "수리남"의 데이터는 며칠간 집계가 안되게 되겠죠.
이를 재처리하려면 Airflow에서 진행을 해주어야 합니다.
1 | SELECT A.* |
이에 비해 LEFT JOIN을 하게 되면 아래처럼 바로 DB 안에서 UPDATE가 가능하게 됩니다.
1 | SELECT A.* |
마치며
사실 업무를 하지 않고 있는 입장에서 이걸 본다면 "무슨 말이야?"라고 치부할 수도 있을 것 같고, 업무를 하는 입장에서는 "걍 하면 되지"라고도 생각하실 수 있습니다.
다만, 이렇게 간단한 일이라도 한 번 정리해놓고 적용하려고 얘쓴다면 재처리하는 순간에 아주 빛을 발할 것으로 생각합니다.
제가 만든 대시보드는 평생 제가 관리합니다. (제 회사만 그런걸까요 ㅎㅎㅎ)
테이블을 마음가는대로 설계하고 나서 재처리할 순간이 온다면 Airflow의 네모 칸들이 채워져가는걸 계속 트랙킹해야할 수도 있겠죠.
생각보다 새로운 지표가 추가되는 일도, 신규 서비스가 나오는 것도 잦다는 것…을 잊지마시며 두 번째 라떼를 호로록 마셔보시길 바랍니다 :>.