LTV (Life Time Value) 지표 속 BG/NBD 모델과 Gamma-Gamma 모델 파헤치기
- 이번 글은 LTV 지표에 대한 내용입니다. 이 포스트
[link]를 주로 참조하였습니다.
LTV (LifeTime Value)란?
LTV는 Lifetime Value, "고객의 생애 가치"라고 불리는 지표로, 고객이 평생동안 기업에게 어느 정도의 가치를 가져다 주는지를 정량화한 지표입니다.
이 LTV는 확률 기반 모형으로 특정한 시점 에서 고객마다 어느 정도의 생애 가치를 가지는지 측정할 수 있도록 합니다.
구체적으로 고객의 생애 가치를 어떻게 추정할까요?
- LTV는 고객의 과거 구매 정보를 가지고
- 미래의 예상 구매 횟수 * 예상 평균 수익으로 계산됩니다.
"고객의 과거 구매 정보"라 함은 크게 네 가지 정보가 필요합니다.
- 첫 구매 ~ 집계일까지의 시간 (Time):
- 첫 구매 ~ 마지막 구매까지의 시간 (Recency):
- 첫 구매 ~ 집계일까지의 구매 횟수 (Frequency):
- 구매 건마다의 구매 금액 (Monetary Value):
미래의 예상 구매 횟수는 첫 구매 ~ 집계일까지의 시간 (Time), 첫 구매 ~ 마지막 구매까지의 시간 (Recency), 첫 구매 ~ 집계일까지의 구매 횟수 (Frequency) 줄여서 "RFM"이라 부릅니다의 정보를 가지고 BG/NBD라는 모델로 추정됩니다.
미래의 예상 평균 수익은 구매 금액 (Monetary Value)의 정보를 가지고 Gamma-Gamma 모델로 추정이 됩니다.
앞에서 확률적으로 모델을 추정한다 말씀을 드렸는데요. 모델 이름도 사실 확률 분포의 이름에서 따왔습니다.
BG/NBD는 베타 분포와 기하 분포의 결합과, 음이항 분포로 구성되고(Beta-Geometric / Negative Binoimal Distribution), Gamma-Gamma는 두 감마 분포의 결합으로 이루어집니다.
구체적인 모형을 설명하기에 앞서 “죽을 때까지 구매하는” (BTYD; Buy Till You Die) 모형어감이 그러니 이제부터 BTYD 모형이라 부르겠습니다의 컨셉부터 설명드리겠습니다.
BTYD 모형을 바탕으로 BG/NBD 모형을 구성합니다.
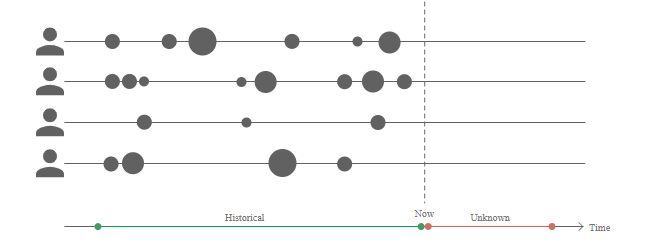
BTYD (Buy Till You Die) 모델

위 그림은 고객 4명의 과거 구매 기록을 도식화한 것입니다. 예를 들어 첫 번째 고객은 6번 구매했고, 세 번째 구매가 컸었네요! 세 번째 고객은 첫 번째 고객보다 구매 주기도 길고 지갑 크기도 작은 고객입니다.
이처럼 BTYD 모델은 과거의 구매 횟수와 구매 금액과 같은 데이터를 바탕으로 고객의 생애 가치를 계산합니다. BTYD는 다음과 같은 질문에 답할 수 있습니다.
- 현재 얼마나 많은 고객들이 남아있나요?
- 지금으로부터 1년 뒤에 얼마나 많은 고객들이 남아있을까요?
- 어떤 고객들이 이탈했었나요?
- 고객들이 한 회사에 미래에 얼마를 소비할까요?
1. 구매 (Transaction) 프로세스 (Buy)
고객이 남아있는 동안, 고객의 구매 횟수는 일정한 기간 동안의 구매율을 모수로 하는 포아송 분포를 따릅니다.
사실 포아송 분포는 "구매 횟수"에 대한 분포라 구매할 확률을 모수로 하지 않고, 정해진 시간 동안의 예상 구매 횟수를 모수로 하는데요.
여기서 전 왜 원 논문에서는 모수를 구매 횟수가 아닌 구매율 (transaction rate)로 표현하는가가 이해가 되지 않았었죠.
아마도 일정한 기간을 어떻게 정의하느냐에 따라서 충분히 비율로 표현할 수 있기 때문이라 생각이 듭니다.
예를 들어, 1년에 30번 구매한 고객이 있다면 구매 횟수가 Pois (30)을 따른다고 말할 수도 있겠지만,
단위 기간을 이보다 더 좁은 기간인 1일로 정의한다면 1일에 (30 / 12개월) / 30일 = 1/12의 확률로 구매를 한다 말할 수 있기 때문에
Pois(1/12)라고 말할 수 있는 것이죠.
이 구매율은 고객마다 다르다고 가정하고, 전체 고객들의 구매율은 Gamma(r,)를 따른다 가정합니다.
2. 이탈 (Dropout) 프로세스 (Till You Die)
각 고객들은 이탈률 를 가집니다. 즉, 고객들은 구매를 한 후에 특정한 확률로 이탈함을 가정하는 것입니다.
이러한 이탈 확률은 고객마다 달라 Beta (a,b)를 따른다 가정합니다.
보통 확률에 대한 분포를 가정할 때 범위가 (0,1)로 정해져있는 베타 분포를 가정하곤 하는데, 감마 분포를 가정한 이유도 위와 같은 이유이지 않을까 생각해봅니다.
고객의 예상 구매 횟수를 계산하는 BG/NBD 모형
위에서 말했듯 BG/NBD 모형은 BTYD 모형에 기반하여 분포를 가정합니다.
구체적으로 분포 가정은 다음과 같습니다.
- 고객이 남아있는 동안, 일정한 기간 동안의 구매 횟수는 Pois()를 따릅니다. 위에서 말씀 드렸듯이 1일 간 Pois (1/12)를 따른다면 T= 1년일 경우 Pois (30)을 따르게 되겠죠! (포아송의 모수인 는 예상 구매 횟수 를 의미합니다)
- 고객마다 일정한 기간 동안 구매하는 횟수는 다릅니다. 이는 ~ Gamma (r, )을 따릅니다.
- j번째 구매가 마지막이고 더 이상 구매를 하지 않을 확률 (이탈률)은 입니다. 이탈할 때까지의 구매 횟수는 Geo (p)를 따릅니다.
- 고객마다 더 이상 구매를 하지 않을 확률 (이탈률)은 다릅니다. 이탈률 p는 p ~ Beta (a,b)를 따릅니다.
- 고객별 일정 기간 동안의 구매 횟수와 구매를 하지 않을 확률은 서로 영향을 주지 않습니다.
여기서 전 두 가지 의문을 가졌었는데요. 대학교 때의 확률 분포 지식을 단전에서 끌어내보았습니다.
NBD (Negative Binomial Distribution) 부분은 어디갔는가?
모형 이름이 BG/NBD인데 B에 해당하는 베타 분포 (Beta Distribution), G에 해당하는 기하 분포 (Geometric Distribution)은 있는 반면 NBD에 해당하는 음이항 분포 (Negative Binomial Distribution)는 어디서도 찾아볼 수 없는 것이 이상했습니다.
결론부터 말하면 **포아송 분포와 감마 분포의 결합이 바로 음이항 분포 (Negative Binomial Distribution)**에 해당합니다. 이를 Poisson-Gamma Mixture라 부릅니다.
대학교 때 여러 확률 분포를 배우는데 이들의 상생 관계를 이해하면 더 깊게 분포를 이해하실 수 있습니다.
예컨대,
- 베르누이 분포가 한 번 시행했을 때의 성공 횟수에 대한 분포라면, 베르누이 분포의 합은 이항 분포로, n번 시행했을 때의 성공 횟수에 대한 분포이며,
- 지수 분포가 사건이 1회 발생할 때까지의 대기 시간에 대한 분포라면, 지수 분포의 합은 감마 분포로, 사건이 n번 시행했을 때까지의 대기 시간에 대한 분포이며,
- 기하 분포가 어떤 사건을 1회 성공할 때까지 걸리는 시행 횟수에 대한 분포라면, 기하 분포의 합은 음이항 분포로, 사건이 r회 성공할 때까지 걸리는 시행 횟수에 대한 분포입니다.
이런 상생 관계 말이죠! 그 중에서 포아송과 감마 분포의 결합은 음이항 분포로 표현이 가능합니다.
포아송 분포와 감마 분포를 결합한다는 건 위에서의 가정처럼 포아송 분포의 모수인 가 감마 분포를 따르도록 만드는 것을 의미합니다.
- X Pois()
- Gamma(r, )
라면 이에 대한 marginal 분포는 다음의 음이항 분포 (Negative Binomial (r,T / ( +T))을 따르게 됩니다.
구체적인 유도 과정은[link]를 참조 바랍니다.
한 줄 요약하면 위의 BG/NBD 모형의 가정 중 포아송 분포와 감마 분포에 해당하는 부분이 결국 "NBD"에 해당하는 부분입니다.
각 분포가 무엇을 의미하길래 왜 이렇게 가정을 했는가?
위 설명 드린 각 분포의 특성은 다음과 같습니다.
- 포아송 분포: 단위 시간 동안의 성공 횟수에 대한 분포
- 감마 분포: 사건을 번 시행할 때까지의 총 시간에 대한 분포
- 기하 분포: 사건이 1번 발생할 때까지의 시도 횟수에 대한 분포
- 베타 분포: 확률에 대한 분포 (범위: (0,1))
예를 들어 봅시다. 2022년 이후 제 컬리 주문 내역을 보니 총 8번 구매했고, 실제 아래와 같이 구매하였습니다.
| 날짜 | 구매 금액 |
|---|---|
| 2022.01.16 | 44,159원 |
| 2022.01.24 | 44,385원 |
| 2022.02.03 | 40,700원 |
| 2022.02.05 | 43,520원 |
| 2022.02.26 | 48,140원 |
| 2022.03.16 | 27,186원 |
| 2022.03.23 | 37,161원 |
| 2022.04.10 | 40,060원 |
- 포아송 분포: 네 달에 거쳐 8번 구매했으니 한 달에 2번 구매한 꼴이 됩니다. 이처럼 한 달의 평균 구매 횟수를 Pois ()를 따른다 가정합니다.
- 감마 분포: 위 내용을 바꿔 말하면 두 번 구매할 때까지 한 달이라는 시간이 걸렸다고 말할 수 있습니다. 이처럼 r번 구매할 때까지 걸리는 시간은 Gamma(r,)를 따른다 가정합니다.
- 기하 분포: 여기서의 사건은 "이탈"입니다. 이탈할 때까지의 총 구매 횟수는 Geo(p)를 따른다 가정합니다.
- 베타 분포: 마지막으로 이 이탈률 p는 Beta(a,b)를 따른다 가정합니다.
고객마다 별개의 과거의 구매 정보 RFM (Recency, Frequency, T)을 가지고 위 분포를 따른다 가정하여 가능도 함수를 구해 기댓값을 구하면 고객마다 다른 예상 구매 횟수를 모델링할 수 있는 것입니다!
고객의 예상 구매 금액을 계산하는 Gamma-Gamma 모델
BG/NBD 모델은 고객마다 다른 구매 횟수를 모델링했다면, Gamma-Gamma 모델은 고객별 구매 금액 정보들을 이용합니다.
Gamma-Gamma 모델은 다음과 같은 가정을 하게 됩니다.
- 고객별 구매 금액은 평균 구매 금액을 중심으로 랜덤하게 분포합니다.
- 고객들의 평균 구매 금액은 고객마다 다르지만, 한 고객의 평균 구매 금액은 시간에 따라 불변합니다.
- 이 평균 구매 금액은 구매 과정과 독립이여야 합니다.
이에 따라 다음과 같이 분포를 가정하여 가능도를 구하게 됩니다.
- 각 구매 건별 구매 금액 는 Gamma (p,v)를 따른다 가정합니다. 총 x번 구매하면 Gamma (px,v)를 따르고, 평균 구매 금액인 는 Gamma(px, vx)을 따르게 됩니다.
(Gamma 분포를 따르는 확률 변수의 합도 Gamma분포를 따릅니다. 자세한 내용은 위키 참조!) - 고객마다 평균 구매 금액이 다르기 때문에 scale 모수인 v 또한 $v \sim \gamma$)를 따른다 가정합니다.
- 이 둘의 관계를 갖고 베이즈 정리를 활용한다면 평균 구매 금액의 marginal 분포는 Gamma (px+q, )를 따르게 됩니다. ( 평균 구매 금액)
그런데 왜 평균 구매 금액에 Gamma 분포를 가정하는가?
궁금하지 않습니까? 아까는 감마 분포가 사건이 r회 일어날 때까지의 총 시간이라 해놓고 평균 구매 금액 도 감마 분포를 따른다고 할까요?
처음 모델을 개발한 Schmittlein and Peterson (1994)는 건별 구매 금액이 정규 분포를 따른다고 가정했다고 합니다.
그러나 이렇게 가정했을 때의 문제는
- 정규 분포는 0보다 아래의 값이 나올 수도 있고
- 대칭적인 분포라는 점입니다.
돈을 쓰는 행위를 생각해보면 무조건 구매 금액이 0원보다 많고, 어떤걸 사느냐에 따라서 가격이 천차 만별이기 때문에 대칭적이지 않습니다.
위 예시는 "컬리에서 식재료를 구매"하는 것이기 때문에 그래도 일관성 있게 4만 원 안팎으로 사긴 하지만, 갑자기 친구들을 초대해서 10만 원을 쓸 수도 있고 가족과 추석을 보내기 위해 20만 원을 쓸 수 있겠죠.
이처럼 구매 금액 자체는 대칭적이기보단 비대칭적이고, 오른쪽으로 치우친 (Right-Skewed) 형태를 띄게 됩니다.
그렇기 때문에 감마 분포가 제격입니다. 0 이상의 값을 가지고, 모수 2개로 비대칭적인 형태를 쉽게 만들 수 있기 때문입니다.
감마 분포가 "시간"의 분포로 쓰일 땐 보통 포아송 분포와 같이 쓰일 때나 그런 것이고, 이 자체로는 0 이상의 범위를 가지고 비대칭적인 분포를 가지는 무언가에 모델링할 수 있는 좋은 분포인 것입니다.
그래서 LTV를 어디에서 활용할 수 있을까
LTV는 앞서 말씀드렸듯이 미래 시점까지의 예상 구매 횟수 * 예상 구매 금액으로 계산합니다.
이 BG/NBD + Gamma-Gamma 모델이 가지는 장점은 고객마다 다른 미래 가치를 계산해주기 때문에 고객 단위의 타겟팅이 가능하다는 점입니다.
고객마다 학습에 들어가는 T (Time), R (Recency), F (Frequency),M (Monetary) 정보와 결합하여
- 구매 빈도 (F)는 낮은데 LTV가 높은 고객
- 구매 빈도 (F), 평균 구매 금액 (M)이 높고 LTV가 높은 고객
- 최근성 ®은 떨어지는데, LTV가 높은 고객
등으로 유저를 분류하여 이에 맞게 고객을 관리하는 것이 가능합니다.
NC 소프트에서는 "광고 성과 측정 방법"을 개선하는 데에 있어
- LTV를 이용해 성과 지표를 개선하고
- LTV를 이용한 퍼널 분석과 최대 허용 광고 단가를 측정하는 데 사용했다 합니다.
그 외에도 "고객의 생애 가치"를 이용해서 어떤걸 할 수 있을지 상상력을 펼쳐보는 것도 좋은 것 같습니다 :> (무궁무진하다!)
마치며
원래의 계획은 Python으로 실행하는 것까지였는데… 다음 번에 lifetimes 패키지를 이용해서 LTV를 추정해보는 실습에 대해 포스팅하도록 하겠습니다.