
XGBoost vs. LightGBM, 어떤 알고리즘이 더 좋을까?
- 오늘은 GBM에 대한 자세한 설명에 이어 GBM 기반의 XGBoost와 LightGBM 알고리즘에 대해 알아보고, 어떤 알고리즘이 더 좋은지 비교하고자 합니다.
- 파이썬 머신러닝 완벽 가이드 책을 참고해 정리하였습니다.
- 실습에 대한 전체 코드는 이 곳에서 확인하실 수 있습니다.
Introduction
XGBoost는 eXtra Gradient Boost의 준말로 GBM에서 파생된 트리 기반의 앙상블 학습 방법입니다. 이 방법은 캐글 대회에서 상위를 차지한 많은 참가자들이 XGBoost를 사용하면서 널리 알려졌습니다. XGBoost는 병렬 학습이 가능해 GBM 대비 학습 시간이 적게 걸리고, 과적합 규제 (Regularization), 나무 가지치기 (Tree pruning), 조기 중단 (Early Stopping) 특정 반복 횟수만큼 더 이상 비용함수가 감소하지 않으면 지정된 반속횟수를 다 완료하지 않고 수행을 종료하는 것과 같은 성능 향상에 필요한 기능들이 탑재되어 있습니다.
LightGBM도 마찬가지로 GBM 기반의 알고리즘이고, XGBoost와 GBM에 비해 훨씬 더 학습에 걸리는 시간이 적다는 점에서 장점을 가집니다. 또한 성능상 XGBoost와도 큰 차이가 없고, 기능상 다양성이 많다는 것도 장점입니다. LightGBM이 XGBoost보다 2년 후에 만들어지다 보니 XGBoost의 장점은 계승하고 단점은 보완하는 방식으로 개발됐다고 합니다.
따라서 이 포스팅에서는 XGBoost와 LightGBM을 파이썬의 사이킷런 (Scikit-liearn) API로 구현하고 이를 산탄데르 고객 예측 데이터에 적용해 어떤 알고리즘이 더 우수한지 판별해보고자 합니다.
사이킷런 (Scikit-liearn) API를 통한 XGBoost
XGBoost의 핵심 라이브러리는 C/C++로 작성되어 있습니다. XGBoost 개발 그룹은 파이썬에서도 XGBoost를 구동할 수 있도록 파이썬 패키지를 제공했습니다. 초기엔 사이킷런과 호환되지 않는 독자적인 XGBoost 전용 패키지였지만, 워낙 파이썬 사용자들이 사이킷런을 기반으로 머신러닝을 많이 이용하고 있기 때문에 XGBoost 개발 그룹은 사이킷런과 연동할 수 있는 API를 제공하기로 했습니다. XGBoost 패키지의 사이킷런 API는 XGBClassifier와 XGBRegressor입니다. 이를 이용하면 사이킷런이 학습을 위해 사용하는 fit()과 predict()과 같은 표준 사이킷런 명령어를 사용할 수 있습니다.
XGBoost 설치
이제 XGBoost를 pip3을 통해 설치해보겠습니다. mac에서 터미널 창을 열어 다음과 같이 명령어를 입력합니다.
1 | pip3 install xgboost |
설치가 완료되면 xgboost 모듈이 정상적으로 설치됐는지 검증합니다.
1 | import xgboost as xgb # 파이썬 래퍼 |
XGBoost의 하이퍼 파라미터
사이킷런 API 기준으로 하이퍼 파라미터를 설명드리겠습니다.
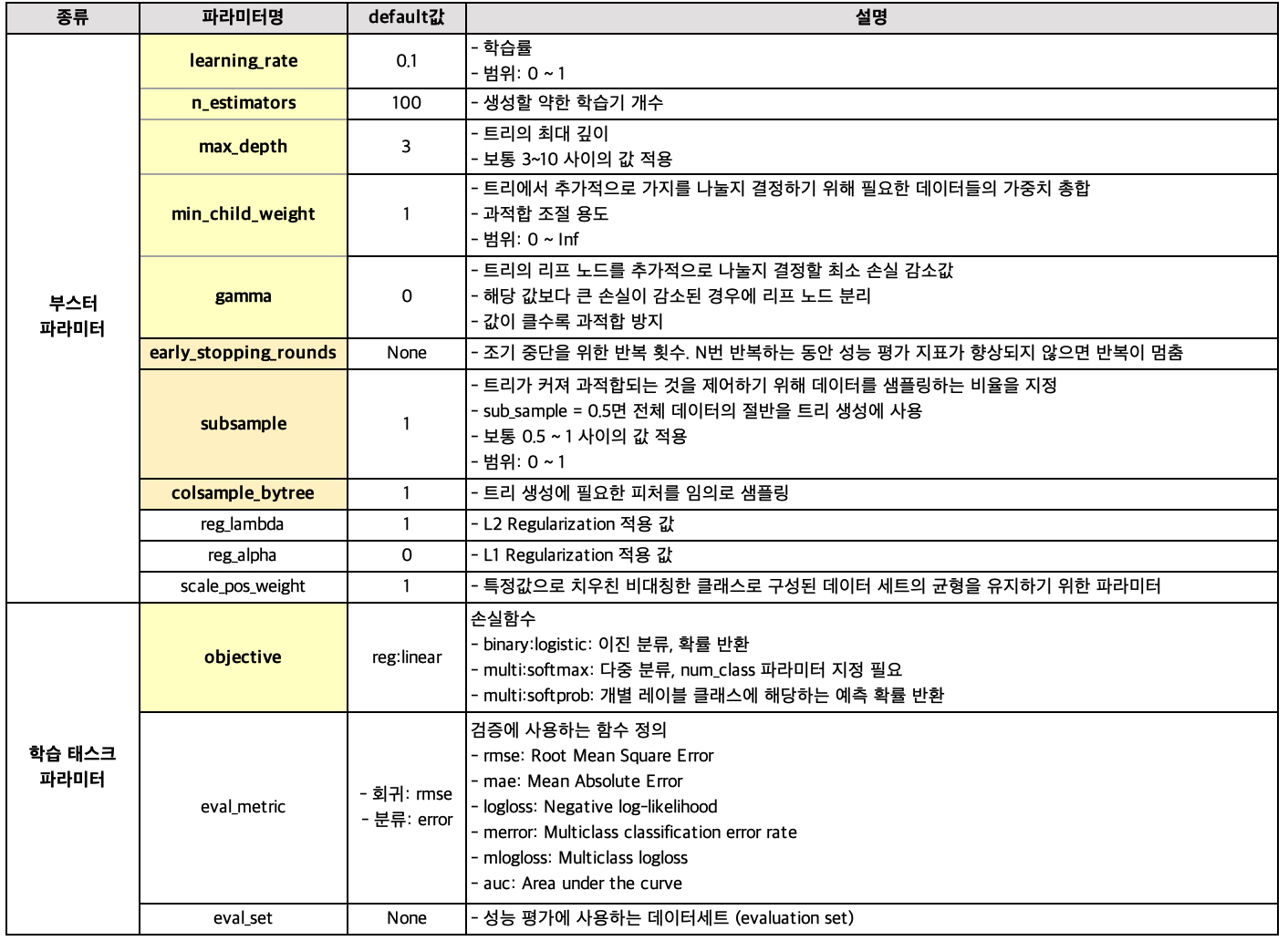
위 표에서 중요도 순으로 정렬하여 색을 다르게 표현했습니다. 즉, learning_rate, n_estimators, max_depth, min_child_weight, gamma의 중요도가 가장 높고, 이후에 early_stopping_rounds, subsample, colsample_bytree를 건드린다 합니다.
자세한 설명은 lightGBM / XGBoost 파라미터 설명을 참조해주시길 바랍니다.
과적합 문제가 심각하면 다음과 같이 하이퍼 파라미터를 조정할 수 있습니다.
- learning_rate을 낮추고 n_estimators를 높여줍니다. (이 둘은 같이 움직입니다)
- max_depth 값을 낮춥니다.
- min_child_weight 값을 높입니다.
- gamma 값을 높입니다.
- subsample, colsample_bytree 값을 조정합니다.
XGBoost 적용
X_train, X_test, y_train, y_test가 있다 할 때 사이킷런을 이용한 학습 및 예측을 하는 방법과 혼동 행렬 (confusion matrix)과 중요도 플랏 (importance plot)을 출력하는 방법은 다음과 같습니다.
1 | from xgboost import XGBClassifier |
사이킷런 (Scikit-liearn) API를 통한 LightGBM
LightGBM을 파이썬에서 적용하는 방법을 알아보기 전에 "왜 LightGBM은 XGBoost나 GBM에 비해 더 빠른 시간 내에 학습할까"에 대한 답을 말씀드리고자 합니다. 이에 대한 답은 노드를 분할하는 방법에 있습니다.
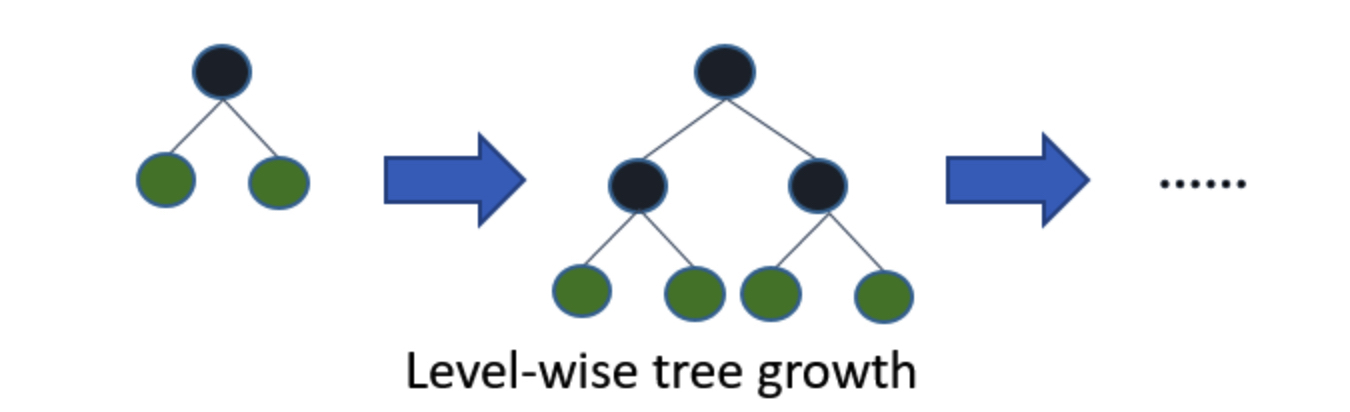
기존의 XGBoost나 GBM은 트리의 깊이를 효과적으로 줄이기 위한 균형 트리 분할 (Level-Wise)을 사용합니다. 최대한 균형 잡힌 트리를 유지하면서 분할하기 때문에 트리의 깊이가 최소화될 수 있습니다. 이러한 균형 잡힌 트리를 생성하는 이유는 과적합을 방지할 수 있다 알려져 있기 때문입니다. 그러나 균형을 맞추기 위한 시간이 오래 걸린다는 단점이 있습니다.
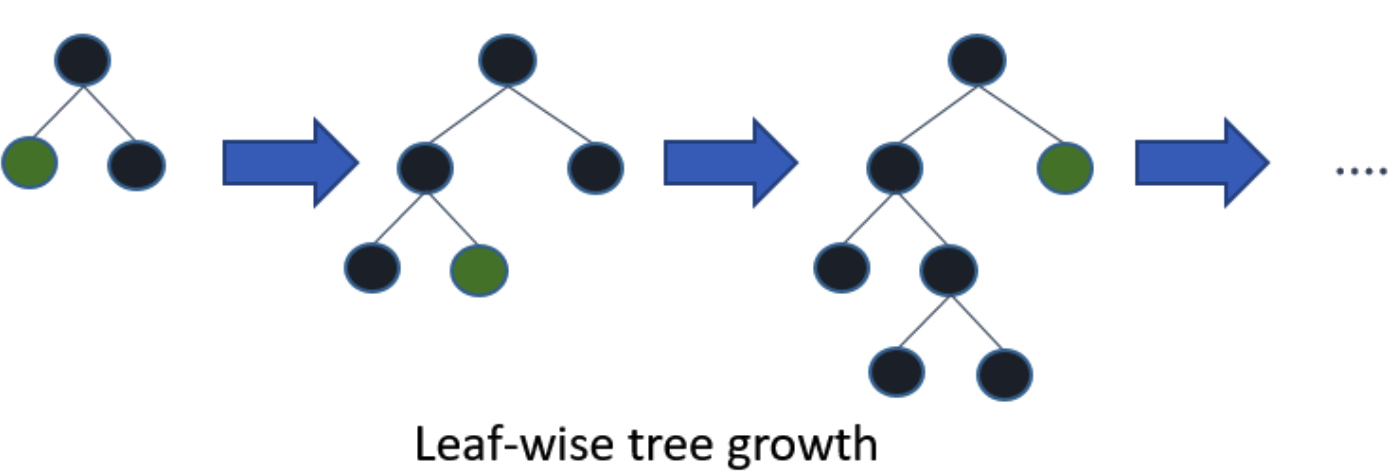
이에 비해 LightGBM의 리프 중심 분할 (Leaf-wise)은 트리의 균형을 맞추지 않고 최대 손실 값을 가지는 리프 노드를 지속적으로 분할하면서 트리의 깊이가 깊어지고 비대칭적인 트리가 생성됩니다. 결과적으로 균형 트리 분할에 비해 손실값이 높은 노드에 대해 더 깊게 트리를 분할하며 손실값을 줄일 수 있기 때문에 다른 부스팅 계열 알고리즘보다 더 좋은 정확도나 비슷한 수준의 성능을 낼 수 있습니다.
Which algorithm takes the crown: Light GBM vs XGBOOST?에 따르면, 리프 중심 분할 방법은 복잡도가 증가하고 과적합 문제가 발생할 수 있다 합니다. 그러나, 이는 트리의 최대 깊이인 max_depth의 하이퍼 파라미터를 조정한다면 해결할 수 있는 문제라 합니다.
LightGBM 설치
XGBoost와 마찬가지로 pip3을 이용해 lightgbm 설치합니다.
1 | pip3 install lightgbm |
잘 설치되었는지 검증해봅니다.
1 | from lightgbm import LGBMClassifier |
LightGBM 하이퍼 파라미터
LightGBM에 사용되는 하이퍼 파라미터는 다음과 같습니다.
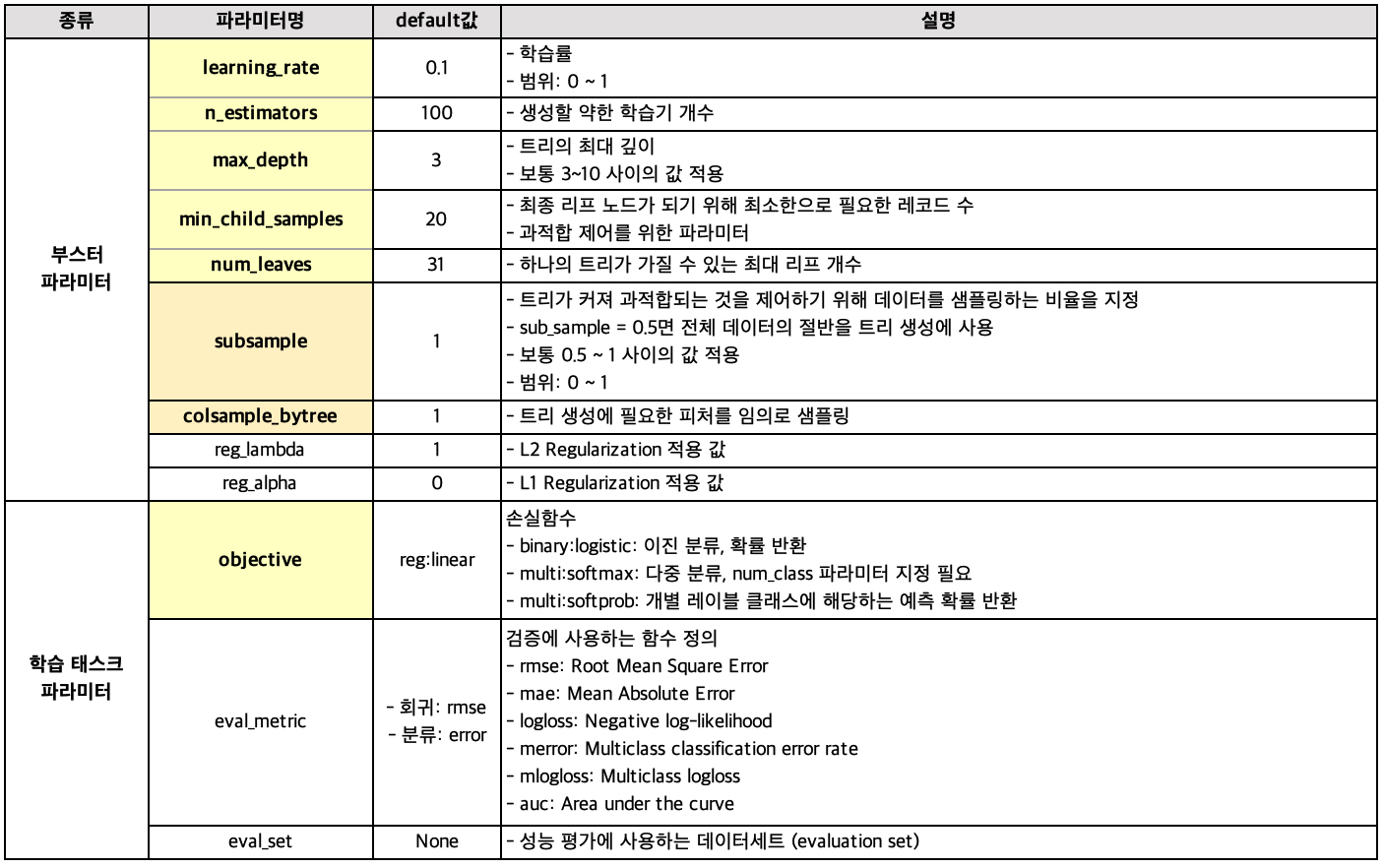
마찬가지로, 중요도 순으로 정렬하였고 자세한 내용은 lightGBM / XGBoost 파라미터 설명을 참조해주시길 바랍니다.
과적합 방지를 위한 하이퍼 파라미터 튜닝 방안은 다음과 같습니다.
- learning_rate를 작게 하면서 n_estimators를 크게 해봅니다.
- min_child_sample는 과적합 개선을 위한 중요한 파라미터입니다. 보통 큰 값으로 설정하면 트리가 깊어지는 것을 방지할 수 있습니다.
- max_depth는 명시적으로 트리의 깊이를 제한합니다.
LightGBM 적용
X_train, X_test, y_train, y_test가 있다 할 때 사이킷런을 이용한 학습 및 예측을 하는 방법과 혼동 행렬 (confusion matrix)과 중요도 플랏 (importance plot)을 출력하는 방법은 다음과 같습니다.
1 | from lightgbm import LGBMClassifier |
XGBoost와 마찬가지로 사이킷런 API를 이용하기 때문에 함수가 거의 비슷합니다 :>
실습: 캐글 산탄데르 고객 만족 예측
이번에는 캐글의 산탄데르 고객 만족 데이터 세트에 대해서 고객 만족 여부를 XGBoost와 LightGBM을 통해 예측해보겠습니다.
분석의 목적은 370개의 피처로 주어진 데이터 세트 기반에서 고객 만족 여부를 예측하는 것입니다. 클래스 레이블 명은 TARGET이고, 1이면 불만을 가진 고객, 0이면 만족한 고객을 의미합니다.
대부분 만족으로 응답한 고객이 많기 때문에 정확도 수치보단 ROC-AUC가 더 적합합니다. 따라서 평가 메트릭은 ROC-AUC로 하였습니다.
필요한 라이브러리
1 | import numpy as np |
데이터 살펴보기
캐글에서 데이터를 다운받아 훈련 데이터를 확인해봅니다.
1 | cust_df = pd.read_csv('./train.csv',encoding='latin-1') |

다음과 같이 76,020개의 행과 371개의 열을 가진 데이터로, 우리가 예측할 변수는 TARGET에 저장되어 있습니다.
1 | cust_df['TARGET'].value_counts() # 0: 만족, 1: 불만족 |
이 TARGET 변수는 이항형 (binary)이고, 만족하는 고객은 73,012명, 만족하지 않는 고객은 3,008명으로 불만족인 고객은 4% 정도에 불과합니다.
1 | 0 73012 |
데이터 전처리하기
describe() 메서드를 이용해 각 피처들의 분포를 살펴보면 다음과 같습니다.
1 | cust_df.describe() |
전처리할 변수는 두 가지입니다.
var3의 최소값이 -999999로 되어 있는데, 이를 가장 값이 많은 2로 변환하고자 합니다. 아마도 특정 예외 값 혹은 null값을 -999999로 변환했기 때문입니다.- ID 피처는 단순 식별자이기 때문에 피처를 드롭하겠습니다.
1 | cust_df['var3'].replace(-999999, 2, inplace=True) |
이제 XGBoost와 LightGBM 모형 훈련을 위해 훈련 데이터와 테스트 데이터를 나누는 작업을 해야 합니다.
이를 위해 sklearn의 train_test_split 메서드를 이용했고, 테스트 데이터의 크기와 훈련 데이터 비율은 2:8로 하였습니다.
그 결과 훈련 데이터의 크기는 (60,816, 369)가 됩니다.
1 | # X랑 y 나누기 |
또한 훈련 데이터와 테스트 데이터 모두 TARGET의 값의 분포가 원본 데이터와 유사하게 전체 데이터의 4% 정도로 불만족 값이 나오도록 만들어졌습니다.
1 | 0 0.960964 |
XGBoost 모델 학습 & 하이퍼 파라미터 튜닝
이제 XGBoost의 학습 모델을 생성하고 예측 결과를 ROC AUC로 평가해보겠습니다 (eval_metric = 'auc'). 또한 시작과 끝 시간을 재어서 XGBoost와 LightGBM의 수행 속도를 비교헤보았습니다.
1 | tic = time.time() #시작 시간 |
Grid Search 없이 약한 학습기 개수 (n_estimators)를 500, 조기 종료 반복 횟수 (early_stopping_rounds)를 100으로 했을 때 걸린 시간은 34초, ROC AUC는 0.8413입니다.
이제 이 성능을 높이기 위한 하이퍼 파라미터 튜닝을 시도해보았습니다. 칼럼 개수가 371개로 많은 편이기 때문에 과적합 방지를 위해 max_depth, min_child_weight, colsample_bytree 하이퍼 파라미터만 일차적으로 튜닝 대상으로 삼았습니다.
다음 예제 코드는 8개 ()의 하이퍼 파라미터의 경우의 수를 가집니다. 수행 시간이 꽤 오래 걸리므로 weak learner의 개수를 100개, fold의 개수를 3개로, early_stopping_rounds를 30으로 줄여서 테스트한 뒤 나중에 하이퍼 파라미터 튜닝이 완료되면 다시 바꾸고자 합니다.
1 | tic = time.time() |
[Output]
1 | Optimized hyperparameters {'colsample_bytree': 0.75, 'max_depth': 5, 'min_child_weight': 3} |
이전에 하이퍼파라미터 튜닝 없이 얻은 ROC AUC 0.8413에 비해, 최적의 파라미터 {‘colsample_bytree’: 0.75, ‘max_depth’: 5, ‘min_child_weight’: 1}로 했을 때 0.002 정도 ROC AUC가 높아졌음을 볼 수 있습니다.
이제 앞에서 구한 최적의 파라미터를 기반으로 다른 하이퍼 파라미터를 변경 또는 추가해 다시 최적화를 진행해보겠습니다. 위에서 구한 최적의 하이퍼 파라미터를 {‘colsample_bytree’: 0.75, ‘max_depth’: 5, ‘min_child_weight’: 1}로 설정한 뒤, n_estimators = 1000으로 증가시키고, learning_rate = 0.02로 감소시키겠습니다. 그리고 reg_alpha = 0.03을 추가하였습니다.
1 | tic = time.time() |
결과적으로 ROC AUC가 0.8450으로 이전 테스트 (0.8413, 0.8433)보다 약간 향상된 결과를 나타내고 있습니다.
그러나, 앙상블 계열 알고리즘은 기본적으로 과적합이나 노이즈에 뛰어난 알고리즘이기 때문에, 하이퍼 파라미터 튜닝으로 성능 수치 개선이 급격히 되는 경우는 많지 않다 합니다. 결과적으로 하이퍼 파라미터 튜닝에 그렇게 의존할 필요는 없어 보입니다!
피처 중요도를 그래프로 나타내면 다음과 같습니다.
1 | from xgboost import plot_importance |
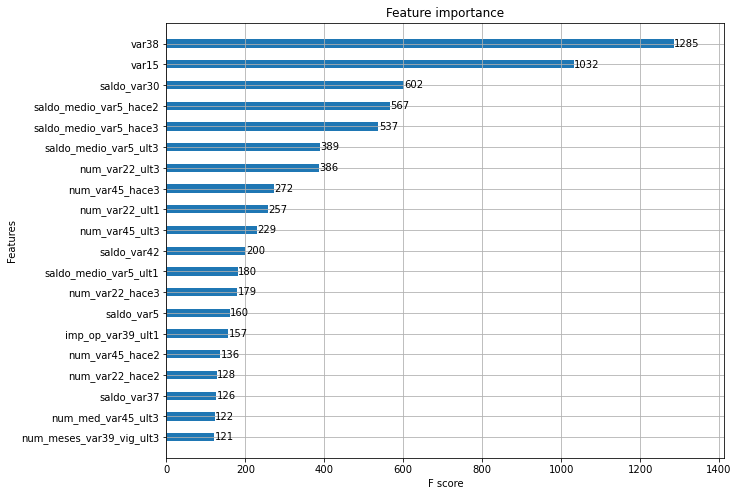
LightGBM 모델 학습 & 하이퍼 파라미터 튜닝
마찬가지로 XGBoost에서 만들어진 데이터 세트를 기반으로 LightGBM 학습을 수행하고 ROC-AUC를 측정해보겠습니다.
1 | tic = time.time() |
결과는 ROC-AUC는 0.8409, 걸린 시간은 1.9초이네요. 튜닝을 하지 않은 XGBoost의 결과와 비교했을 때 ROC-AUC는 0.0004 더 낮고, 시간은 약 32초 더 빠르게 나왔습니다.
마찬가지로 GridSearchCV로 하이퍼 파라미터 튜닝을 수행해 보겠습니다.
1 | tic = time.time() |
크… 엄청납니다. 기존에 3분이 걸렸던 XGBoost의 GridSearchCV에 비해 LightGBM의 GridSearchCV는 46초면 완성이네요! 이의 ROC AUC는 0.8406, 최적의 하이퍼 파라미터는 {‘max_depth’: 128, ‘min_child_samples’: 60, ‘subsample’: 0.8}입니다.
마지막으로 해당 하이퍼 파라미터를 LightGBM에 적용해 다시 학습한 결과입니다.
1 | tic = time.time() |
여전히 ROC-AUC는 0.8406이 도출되었고, 소요 시간은 1.87초입니다.
결과적으로 XGBoost와 LightGBM의 성능과 소요 시간을 비교하면 다음과 같습니다.
| 구분 | XGBoost ROC-AUC (소요 시간) | LightGBM ROC-AUC (소요 시간) |
|---|---|---|
| 튜닝 X | 0.8413 (31초) | 0.8409 (1.8초) |
| 튜닝 O | 0.8450 (77초) | 0.8406 (1.9초) |
소수점 둘째 자리까지 ROC-AUC 값이 같을 정도로 XGBoost만큼 우수한 성능을 낸다는 점, 시간이 훨씬 절약되는 점을 고려했을 때 LightGBM이 완승이라 생각합니다.
실상은 agile하게 하이퍼 파라미터 튜닝 없이 LightGBM을 바로 적용할 것 같다는 생각이 드네요:> 실무에서도 쓰는 날까지!! 기대가 됩니다 후후