과적합 (Overfitting) : 훈련 데이터의 특성에 너무 가깝게 맞춰져서 새로운 데이터에 일반화되기 어려운 경우 일어나는 현상, 주로 모형이 복잡해질수록 훈련 데이터에만 과적합되는 경향을 보임
다중공선성 (Multicollinearity) : 회귀 분석 시 설명 변수 중 두 개 이상의 변수들의 상관관계가 높아 회귀 계수 추정 결과를 신뢰할 수 없는 경우 "다중 공선성"이 존재한다고 말함
정규화 (Regularization) : 모수들의 크기를 제약해 모형을 단순화하여 과적합을 방지하는 한 방법
Trade-off Between Variance and Bias
Ridge/ Lasso 회귀를 본격적으로 배우기 전 이해해야 할 개념은 분산과 편차의 Trade-off입니다. 왜냐하면 Ridge/ Lasso 추정치는 OLS (Ordinary Least Squares) 추정치 (선형 회귀 추정치)에 비해 더 편향되어 있지만 (biased), 분산이 낮아지기 때문에 예측 측면에서 더 좋은 결과를 내기 때문입니다.
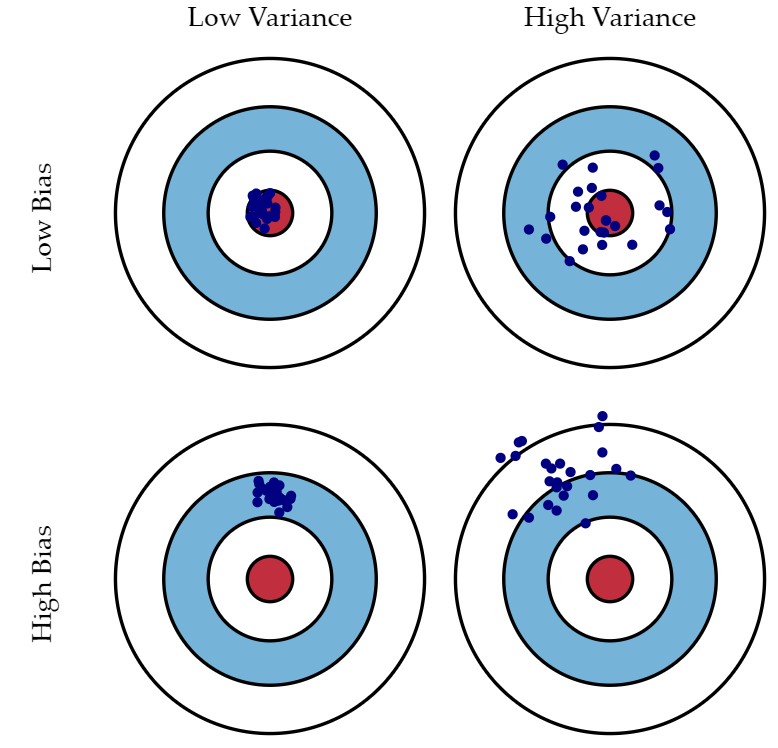
분산과 편차를 도식으로 표현하면 아래과 같습니다. 빨간색 원이 true 값의 영역이고 파란색 점이 예측값들이라 할 때
분산이 낮으면 예측값들이 응집되어 있고, 분산이 크면 예측값들이 퍼져 있습니다.
편차가 낮으면 예측값들이 빨간색 원을 중심으로 모여 있고, 높으면 빨간색 원에서 조금 벗어난 모습을 확인할 수 있습니다. 즉, 편차는 실제 값과 예측값들의 기댓값이 얼마나 차이가 나는 지를 나타냅니다.
고전적인 통계학의 관심사는 데이터에 맞는 모형을 만들고, 이 모형을 해석 (Interpretation) 하는 것이었다면, 최근 기계 학습에서 중시하는 관심사는 예측 (Prediction) 입니다. 즉, 새로운 X0 데이터가 들어왔을 때 이 모형이 얼마나 새로운 값 y0 정확하게 예측하는 지가 중요합니다. (여기서 X를 대문자로 쓰는 이유는 p개의 설명 변수가 있을 때 n×p형태의 행렬 X로 설명변수를 표현하기 때문입니다) 이를 위해 여러 평가 척도 (RMSE, Accuracy, Sensitivity 등)이 개발되어 있습니다.
만약 n개의 훈련 데이터를 T=(Xi,yi,i=1,…,n), 새로운 데이터셋을 (테스트 데이터)를 (X0,y0)라 할 때,
y=f(X)+ε
y는 X의 어떤 모르는 함수꼴로 표현된다 가정합시다 (단순 회귀라면 f(X)=Xβ라 놓을 수 있습니다).
여기서 우리가 최소화하고자 하는 손실 함수 (Loss function)는 예측 오차의 제곱 (Squared Prediction Error)을 최소화하는 것임으로 다음과 같이 정의됩니다.
따라서 예측 오차의 제곱을 최소화하기 위해선 분산인 Var(f(X0))와 편차 Bias(f(X0))를 동시에 낮출수록 좋습니다.
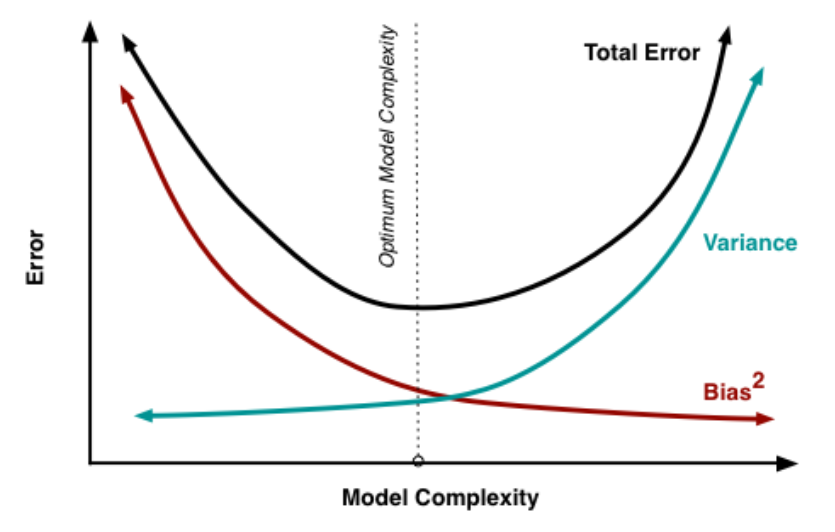
그러나, 분산과 편차를 동시에 낮추는 것은 불가능합니다. 모형이 복잡할수록 새로운 데이터의 적합 값에 대한 분산(Var(f(X0)))은 커지고, 편차는 작아지는 성질을 가지고 있습니다. 이를 분산과 편차의 Trade-off라 부릅니다. 이를 표현하자면 다음과 같습니다.
모형이 복잡할수록 분산이 커지는 이유는 과적합(Overfitting) 때문입니다. 모형이 복잡하다는 뜻은 훈련 데이터의 특성에 딱 맞게 wiggly하게 적합되었음을 시사합니다. 아래의 그림과 같이 오른쪽으로 갈수록 훈련데이터에 딱 맞게 적합되어 복잡성이 높습니다.
훈련 데이터에는 딱 맞지만, 새로운 X0가 들어오면 이 값에 따라 예측값 y0이 민감하게 바뀌고, 일반화가 되어있지 않기 때문에 예측값들의 분산이 큽니다.
관측치의 개수 (n)와 설명변수의 개수(차원) p이 거의 같을 경우 모형이 복잡해져 분산이 커지고 편차는 작아집니다.
모형이 '복잡하다’는 것의 기준은 모수 공간 (parameter space)입니다. 설명 변수가 p개일 경우, 추정해야 하는 모수 β의 공간은 Rp차원이 됩니다. 심지어, n<p의 경우 선형 회귀를 통해 추정치를 내는 것이 불가능합니다.
이에 비해 Ridge/ Lasso 회귀는 모수에 제약을 주어 모형을 더 간단하게 만들어 예측치들의 분산을 낮춰 과적합을 방지합니다! 이렇게 복잡한 모형을 특정한 제약을 통해 더 간단하게 만드는 과정을 정규화 (Regularization) 라 부릅니다. 모형을 더 간단하게 한다는 말은 추정치 β들을 0에 가깝게 만들어 (혹은 0으로 만들어) 설명 변수 X가 반응 변수 y에 주는 영향을 최소한으로 주는 것을 의미합니다.
다중공선성이 있는 데이터
1번과도 연관이 있는 말인데, 보통 고차원 데이터면 다중공선성이 있는 경우가 많습니다. 다중공선성은 통계학에서도 매우 중요한 개념이고 기계 학습을 다룰 때에도 조심해야하는 부분인데요.
설명 변수들끼리 상관관계가 높으면 X의 rank가 감소해 (=linearly dependent, almost singular) OLS 추정치인 β=(X⊤X)−1X⊤Y에서 역행렬 (X⊤X)−1를 구하기 불가능한 경우 다중공선성이 존재한다고 말합니다. 다중공선성 예시, 진단과 해결 방법은 이 곳에서 자세히 볼 수 있습니다.
이 포스트에서 중요한 점은 Ridge/ Lasso 회귀가 다중공선성의 해결책이 될 수 있다는 점입니다. penalty term을 줌으로써 역행렬이 존재하도록 만들기 때문입니다.
선형 회귀에 비해 무엇이 나아졌을까?
더 간단한 모형으로 과적합 방지
분산 감소로 인한 더 좋은 예측력
고차원 데이터 적합 가능
Ridge Regression (L2 penalty)
Ridge regression의 원리
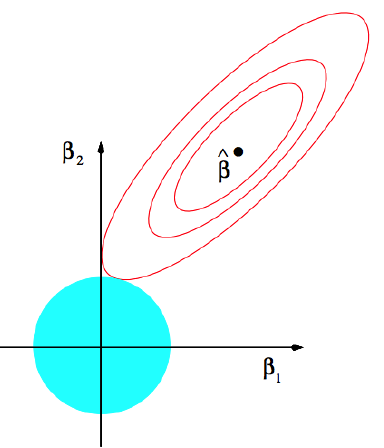
Ridge regression은 모수 공간 Rp를
{β∈Rp:∥β∥22≤t}
로 제한합니다.
Ridge Regression의 estimator βridge는 선형 회귀 estimator βOLS보다 분산이 더 작고 편차는 큽니다.
Ridge regression의 추정
Ridge regression의 해는 OLS estimator에 L2 penalty를 준 방식입니다. OLS estimator는 다음과 같습니다.
βOLS=βargmin(y−Xβ)⊤(y−Xβ)=(X⊤X)−1X⊤y
OLS estimator는 Bias가 없는 비편향 추정치 (Unbiased estimator)로 "BLUE (Best Linear Unbiased Estimator)"라 부릅니다.
그러나 설명변수들 간에 상관관계가 높으면 X의 rank가 감소하여 (X⊤X)가 거의 singular해져 역행렬인 (X⊤X)−1을 구하는 것이 거의 불가능합니다. 이 뿐 아니라, 상관관계가 높으면 β의 분산인 (X⊤X)−1σ2도 매우 커지게 됩니다. 따라서 다중공선성이 있을 경우 OLS estimator의 추정치는 신뢰하기 어렵습니다.
이 대신에 Ridge regression은 OLS estimator에 λ를 더해 역행렬을 계산하기 쉽도록 만듭니다. 즉, Ridge regression estimator는 다음과 같습니다.
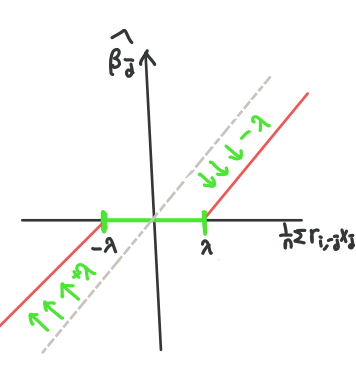
마찬가지로 t가 작을수록, λ가 클수록 모수공간에 대한 제약이 세짐을 의미하고 λ∥β∥1를 L1 penalty라 부릅니다.
이 제약 조건을 그림으로 이해하면,
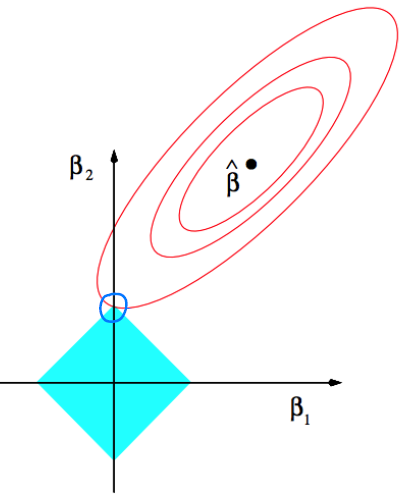
Ridge 그림과 마찬가지로 빨간색 타원은 RSS를 의미합니다.
파란색 사각형은 Lasso의 제약조건인 ∥β∥1≤t를 ∣β1∣+∣β2∣≤t로 표현한 것입니다.
따라서 RSS를 최소화하는 데 제약조건을 만족해야하므로, Lasso regression의 해는 빨간색 타원과 파란색 사각형의 접점이 됩니다.
여기서 주목할 점은 접점이 β1이 0인 지점 (파란색 원)이라는 것입니다. 즉, Lasso는 Ridge와 달리 몇 개의 모수는 0으로 추정하여 sparse solution을 내는 특징을 가집니다. sparse하다는 말은 해가 "드문드문"있고 나머지는 0인 경우를 의미합니다.
Stochastic Coordinate Descent Algorithm
Stochastic Coordinate Descent algorithm은 j번째 특성을 랜덤하게 고르고, 이를 좌표축을 따라 최적화하는 방법으로, Lasso의 해를 구하기 위해 쓰이는 방법입니다.
Lasso의 목적함수 Q(β)=Q(β1,…,βp)를 벡터형식으로 쓰면 다음과 같습니다. 여기서 1/n대신 1/2n으로 쓰는 이유는 단순히 미분했을 때 쉽게하기 위함입니다. 우리는 Q(β)를 최소화할 βj,j=1,…,p를 찾는 것이 목표입니다.