Python boto3으로 AWS S3 버킷 생성 및 파일 올리기
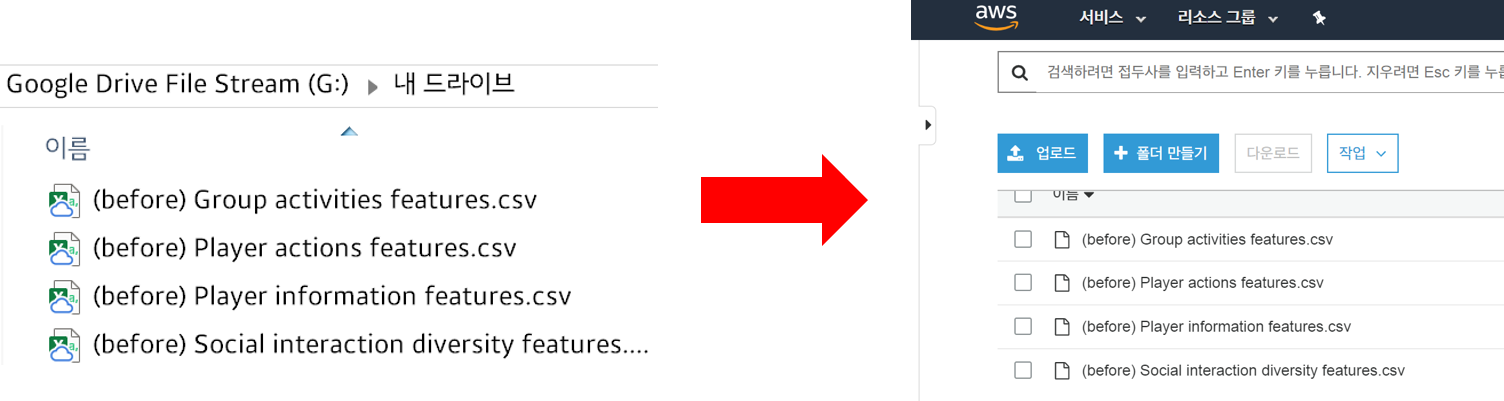
- 목표는 사진처럼 local 폴더에 있는 파일들을 AWS S3Simple Storage Service의 버킷 (가상 저장소)에 올리는 것입니다.
- 전체 코드는 여기서 확인할 수 있습니다.
Introduction
먼저 API와 SDK에 대해 이해하면 boto3으로 S3을 제어하는 방식을 알 수 있습니다.
API: AWS가 IT 자원에 접근하는 방식
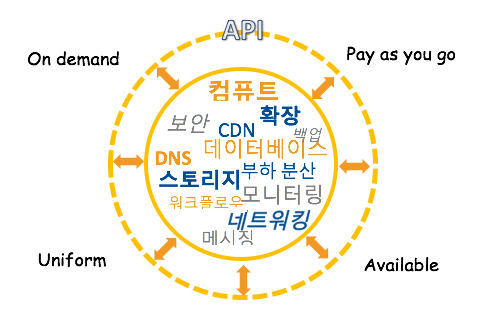
AWS는 API Application Programming Interface를 통해 EC2 인스턴스에 접속하거나, 1TB 저장소를 만들거나, 하둡 클러스터를 시작하는 등의 IT 자원들을 제어할 수 있는 인프라를 제공합니다.
즉, AWS가 IT 자원에 접근하기 위해서는 API를 호출해야합니다.
API를 호출하는 3 가지 방법
직접 API를 호출하는 방법은 약간 복잡하기 때문에 직접하기보단 크게 3 가지 방법을 통해 API를 호출합니다.
- AWS Console
- CLICommand Line Interface, 명령줄 인터페이스
- SDKSoftware Development Kit
여기서 우리에게 익숙한 건 AWS Console입니다. AWS 홈페이지에 들어가 루트 이용자로 로그인해서 서비스를 선택한 후 볼 수 있는 화면이 바로 콘솔이죠.

그러나 AWS Console은 로그인 후 항상 개발자 또는 오퍼레이터가 콘솔에 접속해 클릭 클릭을 해서 원하는 IT 자원을 이용하는 방식이기 때문에 번거로운 방법입니다.
이보다 인프라를 자동화할 목적으로 CLI나 SDK를 사용합니다. CLI는 명령줄에서, SDK는 프로그래밍 언어로 AWS를 제어하는 방법입니다. AWS를 제어할 수 있는 대표적인 SDK는 안드로이드, Node.js, php, Python, Java, Ruby 등이 있습니다.
boto3: AWS를 제어하기 위한 Python 라이브러리
따라서, 이 포스트에서는 SDK 중 Python의 boto3 라이브러리를 이용해서 AWS를 제어하는 방법을 알아보고자 합니다. 그 중, 로컬 저장소 (내 컴퓨터)에 저장되어 있는 파일을 AWS S3 (가상 저장소)에 파일을 올리는 방법에 대해 써보겠습니다.
S3: AWS에서 제공하는 저장공간
S3는 인터넷 스토리지 서비스로 용량에 관계 없이 파일을 저장할 수 있고 웹(HTTP 프로토콜)에서 파일에 접근할 수 있는 장점을 가지고 있습니다. S3에서 알아야 할 개념은 **버킷 (Bucket)**과 **객체 (Object)**입니다.
S3에 데이터(사진, 동영상, 문서 등)를 업로드하려면 우선 하나의 AWS 리전에 S3 버킷을 만들어야 합니다. 버킷 안에 객체를 업로드하는데, 객체는 키-값key-value으로 구성된 것으로 키는 객체에 지정한 이름을, 값은 저장하는 콘텐츠를 의미합니다.
즉, 로컬 저장소에서 한 폴더에 여러 파일들을 올리듯이 버킷은 폴더에, 객체는 파일에 해당합니다. 한 버킷을 생성하고 그 안에 여러 객체 (파일)들을 올릴 수 있습니다.
S3 프리티어 요금
AWS 신규 가입 고객은 1년 동안 매달 5GB의 Amazon S3 스토리지(S3 Standard), 20,000건의 Get 요청, 2,000건의 Put 요청, Delete 요청, 15GB의 데이터 전송이 무료입니다. 여기서 Put은 데이터를 업로드, Get은 데이터를 가져오는 명령을 의미합니다.
Procedures
이제 boto3을 사용해서 AWS의 S3 버킷을 생성하고 파일을 업로드하는 과정을 살펴봅시다.
IAM 사용자 생성하기
가장 먼저 해야할 일은 IAMIdentity and Access Management, 인증 및 접근관리 서비스 사용자를 생성하는 것입니다. IAM 서비스는 AWS 계정으로 누가 무엇을 할 수 있는 지에 대해 제어합니다. 즉 IAM 사용자와 그의 접근 권한 (S3에 접속 가능, EC2 생성 가능 등의 권한)을 등록해서 해당 권한을 부여받은 사용자만 AWS 계정에 접속할 수 있는 것입니다.
IAM 사용자 생성 방법은 다음과 같습니다.
좌측 상단의 서비스 > IAM > 액세스 관리 > 사용자 > 사용자 추가클릭

사용자 이름을 지정하고,AWS 액세스 유형을프로그래밍 방식 액세스로 체크

권한 설정>기존 정책 직접 연결에서s3검색 후AmazonS3FullAccess클릭
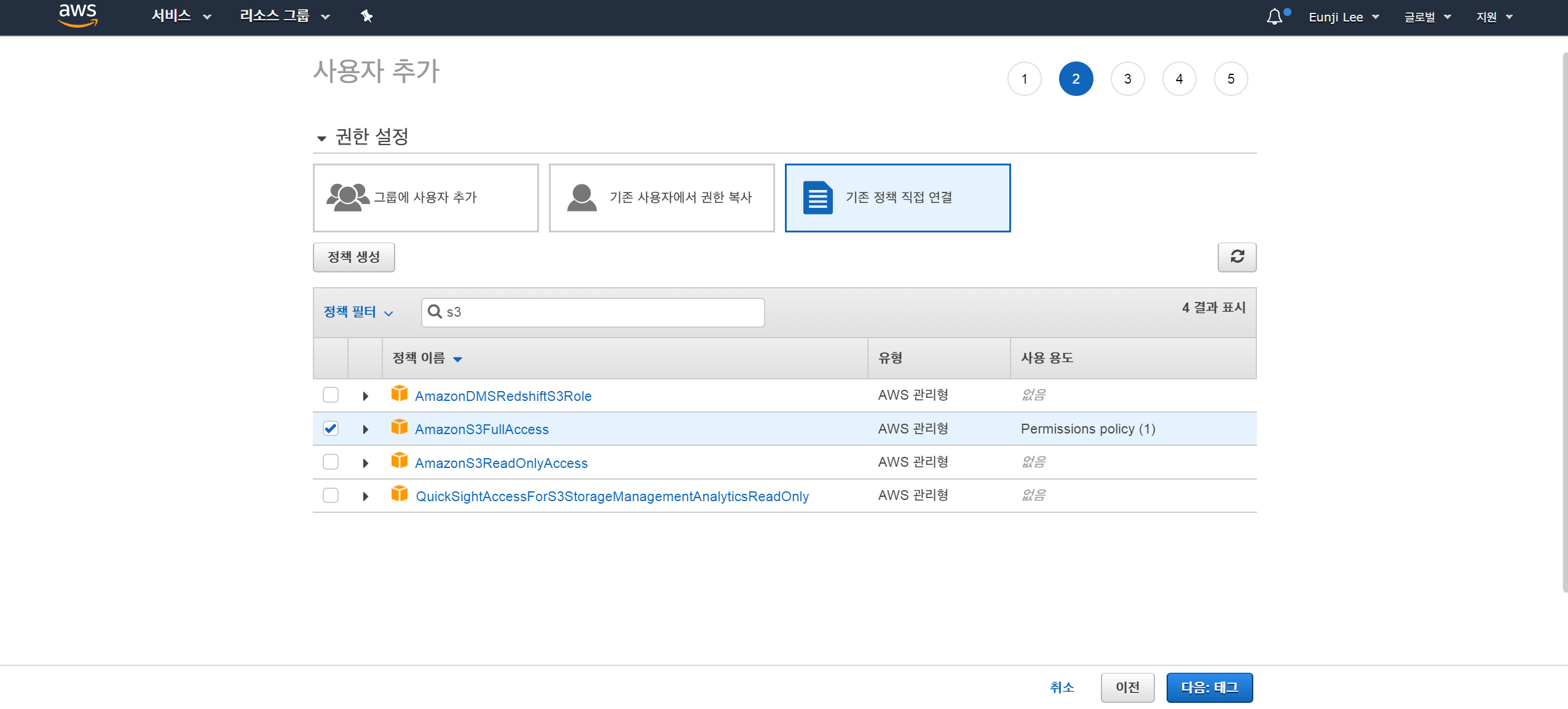
다음:태그 > 다음:검토클릭 후.csv 다운로드
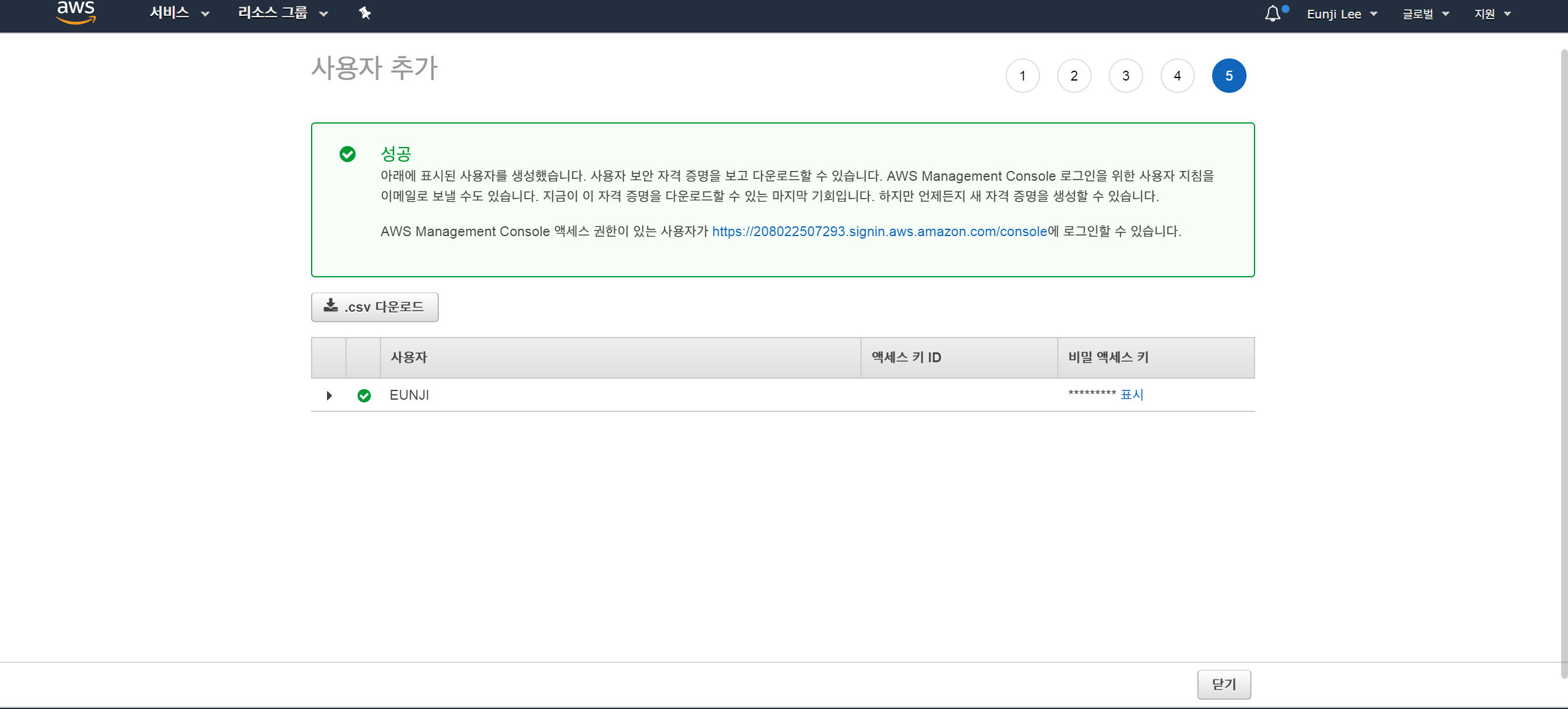
3번의 과정에서 해당 사용자에 S3을 완전히 접근할 수 있는 권한을 부여하였습니다.
또한, 4번의 과정에서 꼭 .csv 다운로드를 눌러 파일을 안전한 곳에 저장합니다.
다운로드 받은 csv파일은 IAM 사용자의 access id와 access key를 포함하고 있습니다.
boto3으로 S3 접속 및 버킷 생성
먼저 명령프롬프트에 pip install boto3으로 boto3라이브러리를 설치합니다.
이후, boto3을 import해서 다음과 같이 기존에 있는 버킷 이름이면 에러메세지를 출력하고, 그렇지 않으면 새로 버킷을 생성하는 create_s3_bucket함수로 버킷을 생성합니다. (출처: 삐멜님 블로그)
1 | import boto3 |
- 아까 받은 csv파일을 열어
YOUR_ID부분에access_id,YOUR_KEY에access_key를 넣어줍니다. LocationConstraint에 있는 인자를 써주지 않으면,us-east-1이 default로 지정되므로 저희는 서울에 해당하는ap-northeast-2를 입력합니다.BUCKET_NAME_YOU_WANT에 원하는 버킷 이름을 적어줍니다.
파일 업로드
다음은 생성한 버킷에 로컬 파일을 올리는 과정입니다.

위 사진의 G:\내 드라이브에 있는 4개의 파일을 올리려합니다. 코드는 다음과 같습니다.
1 | import os |
files는 로컬 저장소에서 가져올 파일명입니다. 만약 데이터가 있는 경로가 파이썬 코드가 있는 곳과 다르다면 경로를 포함해서 파일명을 불러와야겠죠. 파일 이름이 모두 (before)로 시작하기 때문에 glob모듈을 통해 경로를 포함한 파일명을 불러왔습니다. files를 출력하면 다음과 같이 나옵니다.
1 | [1] files |
stored_names는 생성한 버킷에 올릴 파일명입니다. "G:/내 드라이브"는 이름에 필요없으니까 map을 통해 리스트 하나의 element마다 lambda함수를 적용한 후 다시 list로 만들었습니다. stored_names를 출력하면 다음과 같습니다.
1 | [1] stored_names |
마지막으로 upload_file 메서드로 버킷에 파일을 하나씩 업로드합니다.
1 | for file,name in zip(files,stored_names): |
file은 앞의 files객체의 각 요소를, name은 stored_names의 각 요소를 의미합니다.

이처럼 AWS Console을 이용해서 진짜 S3에 내 버킷이 생성되었고 버킷에 파일들이 업로드 되었는 지 확인했습니다.
What’s Next?
지금까지 boto3라이브러리를 이용해서 AWS 계정에 접속해서 S3 버킷을 생성하고 파일들을 업로드하는 방법에 대해 알아봤습니다.
다음 포스팅에서는 AWS RDS 중 MySQL을 생성하고 S3과 연결하는 방법에 대해 알아보겠습니다.